GPT-4o has a few tricks up its sleeve that OpenAI hasn't talked about

While OpenAI's presentation of GPT-4o focused primarily on its speech and audio capabilities, the model's true distinction is its multimodal foundation.
GPT-4o accepts any combination of text, audio, images, and video as input, and produces any combination of text, audio, and images as output.
Following GPT-4o's unveiling, OpenAI demonstrated some of these capabilities in its blog.
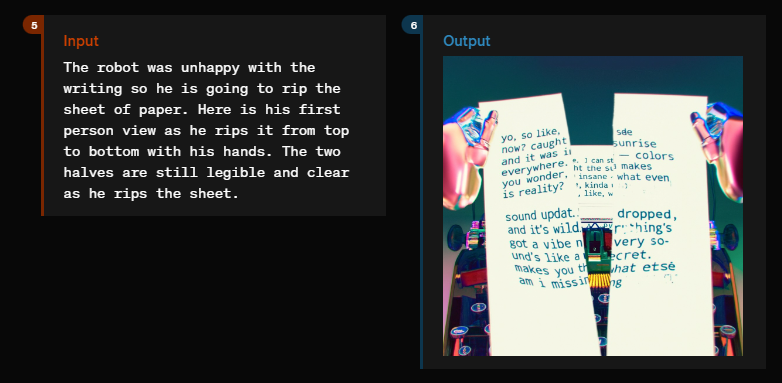
For example, the model can generate visual narratives. In one example, a robot writes several diary entries on a typewriter. The story is written on a sheet of typewriter paper, which is shown in an image. The model can take the scene further and show the robot tearing up the page because it is unhappy with what it has written.
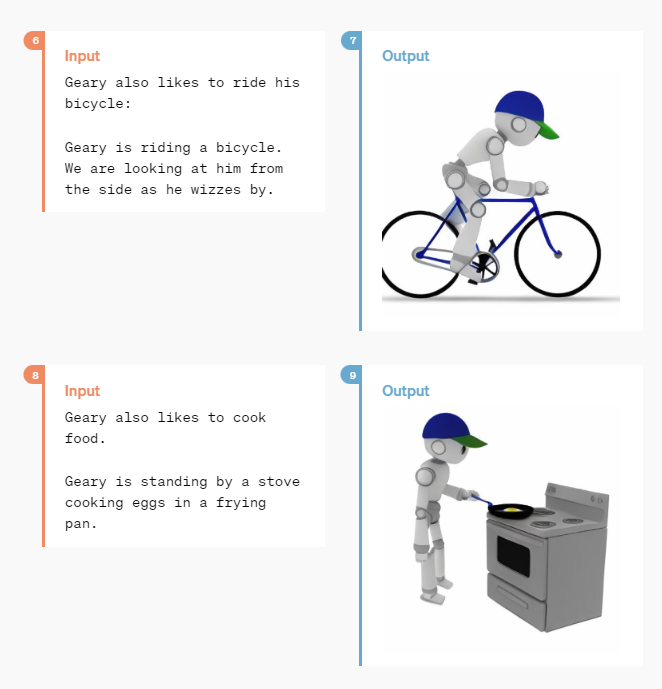
The model can also create detailed and consistent character designs for movies or stories. One demo creates the robot Geary, who plays baseball, programs, rides a bike, and cooks.
Another example is Sally, a postal worker who delivers a letter and then panics because it is being chased by a golden retriever, one of the most dangerous species on earth.

GPT-4o can also generate various creative typographic styles. For example, it can output a poem directly as a designed sheet of paper or even develop new fonts.

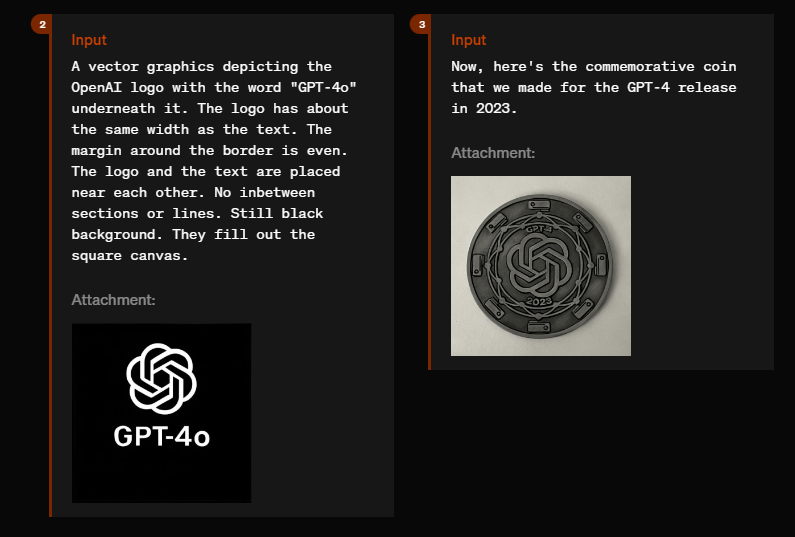
In another example, GPT-4o designs a commemorative coin, such as the one issued to celebrate the release of GPT-4 in 2023. Futuristic or old Victorian typefaces are also supported.
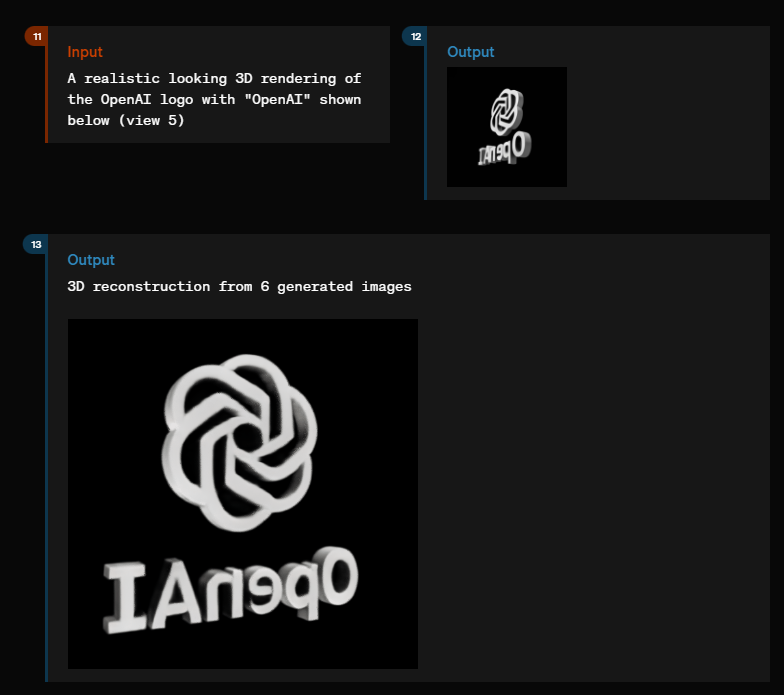
GPT-4o can even generate 3D renderings of objects such as the OpenAI logo or sculptures and display them from different angles.
Finally, the demos show that the model seems to understand causal relationships in images to some extent. The task is to visualize three cubes with the letters "G", "P", and "T" stacked on top of each other. The order of the letters (G, P, T) and the order of the colors (red, blue, green) must be correct.
This test has long been considered a benchmark for image generators' understanding of the world, and GPT-4o seems to pass it reliably over many trials in this particular demonstration, with only one example showing a slight inconsistency in color order (6/7).

Other examples include placing logos on objects, transcribing and summarizing audio and video material, and transforming photos of people into new situations like movie posters or cartoon styles.

The wealth of capabilities makes it clear that GPT-4o is a step toward an Omni model that understands and generates text, images, audio, and eventually video.
Prafulla Dhariwal, Head of Omni Development, describes Omni as the first "first natively fully multimodal model" and its introduction as a "huge, org-wide effort".
The new tokenization indicates that the model has been developed from scratch. GPT-4o could be a precursor of sorts to GPT-5, which has now been released as a standalone model. According to speculation, Omni has been in the works since 2022.
It remains to be seen when and to what extent the individual multimodal capabilities will be available in ChatGPT or via API, and how they will compare to standalone models for 3D or image generation, for example.
As OpenAI itself says: "Because GPT-4o is our first model combining all of these modalities, we are still just scratching the surface of exploring what the model can do and its limitations."
OpenAI promises an iterative rollout, with audio capabilities coming first.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.