OpenAI's new method shows how GPT-4 "thinks" in human-understandable concepts

OpenAI has made a new way to break down the inner workings of GPT-4 into 16 million patterns in often human-understandable features. The results can help humans better understand the safety and robustness of AI models.
Even with a lot of progress in research and development, large AI models are still "black boxes" - they work, but we don't know exactly how yet.
OpenAI now demonstrates a method for finding "features" in large AI models - patterns of activity in neural networks that humans can ideally make sense of.
The company uses "sparse autoencoders" for this. An autoencoder is a neural network that learns to reconstruct its input as accurately as possible, and OpenAI used the internal activations of GPT-4's neural nets as input for the autoencoder.
The autoencoder must then learn to break down the complex activation patterns into more compact, interpretable features. A "sparse" representation, in which most features are inactive and only a few are active, is used to simplify interpretation. To achieve this, the autoencoder must filter out only the most important features.
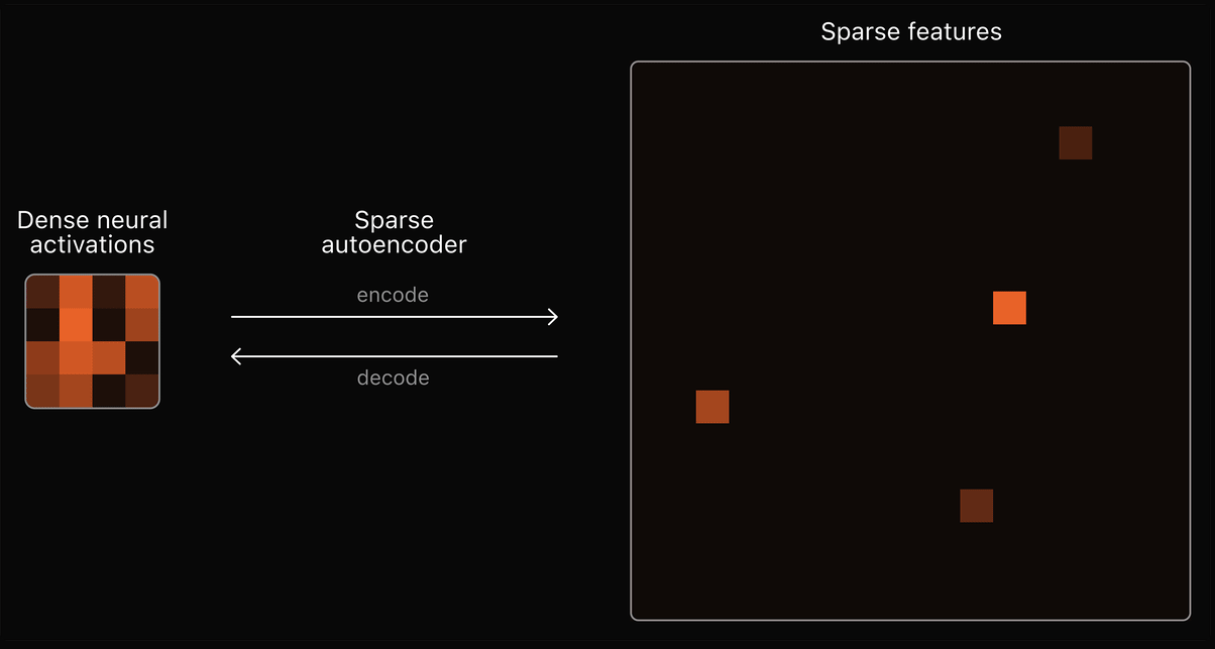
Each feature that the autoencoder learns then ideally matches a concept that GPT-4 uses inside that humans can understand, such as certain grammar rules, world facts, or logical reasoning. By looking at the learned features, we can then figure out how GPT-4 "thinks," the theory goes.
OpenAI scales its analysis tool
The big challenge is that GPT-4 likely uses millions or even billions of these concepts. Old autoencoders were too small to handle this huge number of features.
OpenAI has now found a way to make these autoencoders handle millions of features, and has trained a 16 million feature autoencoder for GPT-4 to test it.
The company found specific features in GPT-4, such as for human flaws, price increases, ML training logs, or algebraic rings. However, many of these features were difficult to understand or showed activity unrelated to the concept they represented.
Moreover, the sparse autoencoder doesn't show everything the original model can do. To show all the features, it would have to be scaled up to billions or even trillions of features, OpenAI says, adding that this "would be challenging even with our improved scaling techniques."
OpenAI has published the paper, released the source code on Github and, and built an interactive visualizer for the learned features of the autoencoder.
OpenAI's competitor Anthropic recently published similar research on understanding a language model. The results show that a better understanding of the models can directly change the way they work. So research into interpretability is not just about safety and ethics - it is also about performance and use cases.
Like OpenAI, Anthropic found that scaling the analysis method was the biggest challenge. The computing power required would be many times greater than what's used to train the model, the company said.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.