DeepSeek-Coder-V2: Open-source model beats GPT-4 and Claude Opus

The academic research collective DeepSeek-AI has released the open-source language model DeepSeek-Coder-V2. It aims to compete with leading commercial models like GPT-4, Claude, or Gemini in code generation capabilities.
DeepSeek-Coder-V2 builds on the previous DeepSeek-V2 model and has been additionally trained on 6 trillion tokens from a high-quality multi-source corpus. The model now supports 338 programming languages, up from 86, and can process contexts of up to 128,000 tokens, up from 16,000.
The training dataset consists of 60% source code, 10% mathematical data, and 30% natural language. The code portion contains 1.17 trillion tokens from GitHub and CommonCrawl, while the mathematical part includes 221 billion tokens from CommonCrawl.
DeepSeek-Coder-V2 uses a Mixture-of-Experts architecture and comes in two variants: The 16-billion-parameter model has only 2.4 billion active parameters, while the 236-billion model has just 21 billion. Both versions have been trained on a total of 10.2 trillion tokens.
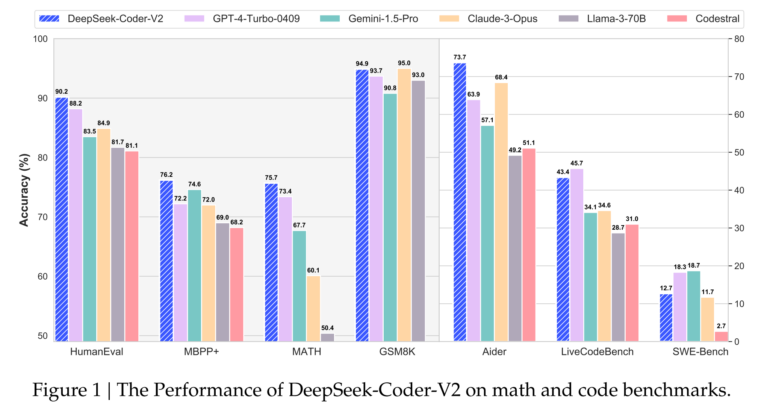
DeepSeek-Coder-V2 breaks the dominance of closed models
In benchmarks like HumanEval or MBPP, DeepSeek-Coder-V2 can keep up with the best commercial models, according to DeepSeek-AI. The 236-billion version achieved an average of 75.3%, slightly lower than GPT-4o's 76.4% but better than GPT-4, or Claude 3 Opus.
In mathematical benchmarks such as GSM8K, MATH, or AIME, DeepSeek-Coder-V2 is on par with the leading commercial models. In language tasks, it performs similarly to its predecessor, DeepSeek-V2.
The DeepSeek-Coder-V2 model is available for download on Hugging Face under an open-source license. It can be used for both research and commercial purposes without restrictions. It is also accessible via an API.
Despite the impressive results, the developers see room for improvement in the model's ability to follow instructions. This is crucial for handling complex programming scenarios in the real world, which DeepSeek-AI aims to work on in the future.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.