Training language models on synthetic programs hints at emergent world understanding

A new study by researchers at MIT indicates that large language models (LLMs) could develop their own understanding of the world as their language competence increases, rather than just combining superficial statistics.
Researchers at the Massachusetts Institute of Technology (MIT) have found evidence that large language models (LLMs) may develop their own understanding of the world as their language abilities improve, rather than merely combining superficial statistics. The study contributes to the debate on whether LLMs are just "stochastic parrots" or can learn meaningful internal representations.
For their investigation, the researchers trained a language model with synthetic programs to navigate 2D grid world environments. Although only input-output examples, not intermediate states, were observed during training, a probing classifier could extract increasingly accurate representations of these hidden states from the LM's hidden states. This suggests an emergent ability of the LM to interpret programs in a formal sense.
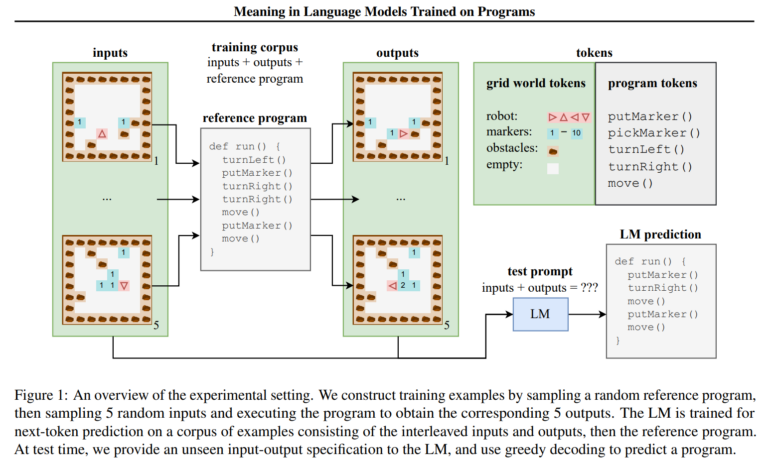
The researchers also developed "semantic probing interventions" to distinguish what is represented by the LM and what is learned by the probing classifier. By intervening on semantics while preserving syntax, they showed that the LM states are more attuned to the original semantics rather than just encoding syntactic information.
OthelloGPT also showed meaningful internal representations
These findings are consistent with a separate experiment where a GPT model was trained on Othello moves. Here, the researchers found evidence of an internal "world model" of the game within the model's representations. Altering this internal model affected the model's predictions, suggesting it used this learned representation for decision-making.
Although these experiments were conducted in simplified domains, they offer a promising direction for understanding the capabilities and limitations of LLMs in capturing meaning. Martin Rinard, a senior author of the MIT study, notes, "This research directly targets a central question in modern artificial intelligence: are the surprising capabilities of large language models due simply to statistical correlations at scale, or do large language models develop a meaningful understanding of the reality that they are asked to work with? This research indicates that the LLM develops an internal model of the simulated reality, even though it was never trained to develop this model."
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.