WonderWorld AI generates interactive 3D environments from photos in just 10 seconds

Researchers at Stanford University and MIT have developed an AI system that can interactively generate 3D scenes from a single image.
Researchers at Stanford University and MIT have developed an AI system that can interactively generate 3D scenes from a single image in real-time. This new technology, called WonderWorld, enables users to build and explore virtual environments step-by-step by controlling the content and layout of generated scenes.
The biggest challenge in developing WonderWorld was achieving rapid 3D scene generation. While previous approaches often required dozens of minutes to hours to generate a single scene, WonderWorld can produce a new 3D environment within 10 seconds on an Nvidia A6000 GPU. This speed allows for real-time interaction, a significant advancement in the field.
Video: Yu, Duan et al.
WonderWorld works by starting with an input image and generating an initial 3D scene. It then enters a loop, alternating between creating scene images and corresponding FLAGS representations. Users can control where new scenes are generated by moving the camera and use text input to specify the type of scene they want.
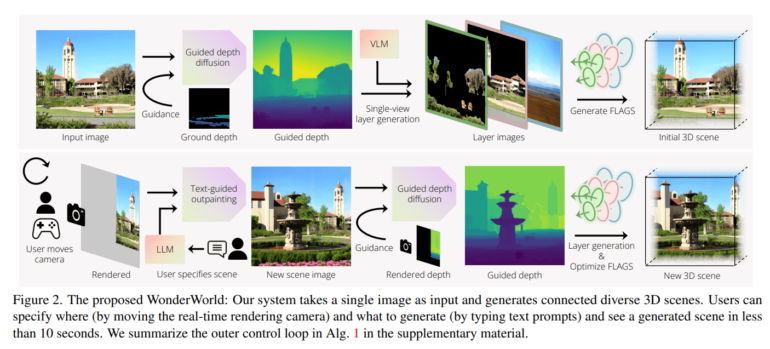
The FLAGS representation consists of three layers: foreground, background, and sky. Each layer contains a set of "surfels" - elements defined by their 3D position, orientation, scale, opacity, and color. These surfels are initialized using estimated depth and normal maps, then optimized to create the final scene.
To reduce geometric distortions at scene transitions, WonderWorld employs a guided depth diffusion process. This uses a pre-trained diffusion model for depth maps, adjusting the depth estimate to match the geometry of existing parts of the scene.
Team sees potential in game development
Experiments have shown that WonderWorld significantly outperforms previous methods for 3D scene generation in terms of speed and visual quality. In user studies, the generated scenes were rated as more visually convincing than those produced by other approaches.
Video: Yu, Duan et al.
Video: Yu, Duan et al.
However, the system does have some limitations. It can only create forward-facing surfaces, restricting user movement to about 45 degrees in the virtual world. The generated worlds currently look like paper cut-outs. The system also struggles with detailed objects like trees, which can lead to "holes" or "floating" elements when the viewing angle changes.
Despite these limitations, the researchers see significant potential for WonderWorld in various applications. Game developers could use it to build 3D worlds iteratively. It could generate larger and more diverse content for virtual reality experiences. In the long term, it could enable users to create freely explorable, dynamically evolving virtual worlds.
You can find more examples to try out for yourself on the WonderWorld project page.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.