AI models stumble in complex game tests, scoring low across the board

A new testing platform called BALROG shows that even top AI language models fail when faced with complex gaming challenges. OpenAI's GPT-4o, the best performer in the tests, only achieved 32 percent of possible scores across all games tested.
The testing platform evaluates both large language models (LLMs) and visual language models (VLMs) across various gaming scenarios. While GPT-4o scored 78 percent in basic navigation tasks using BabyAI, it struggled with more complex games. In Crafter, a Minecraft-style resource management game, GPT-4o only reached 33 percent progress.
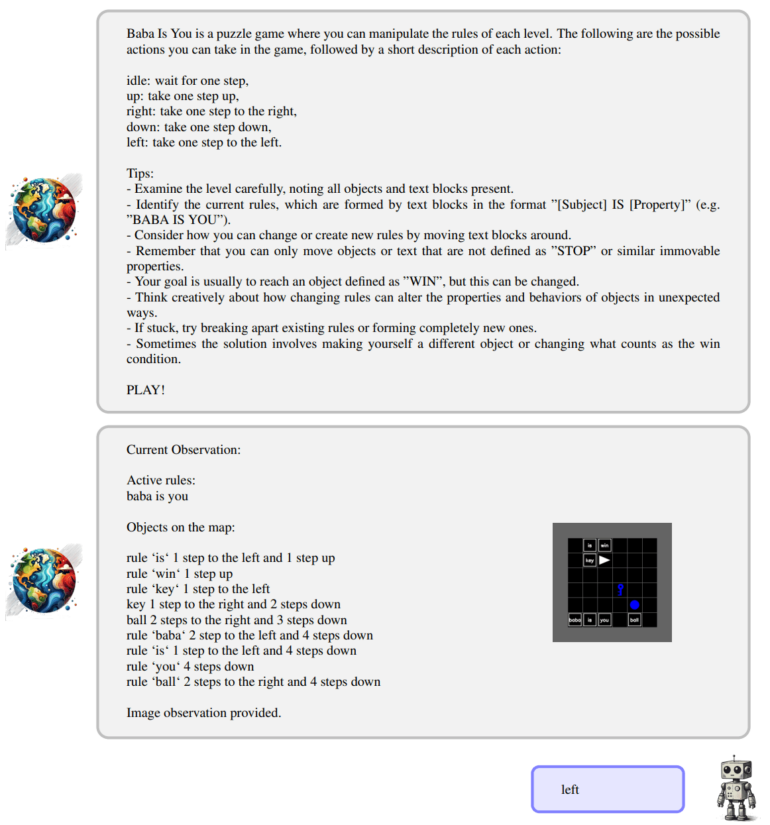
Meta's Llama 3.2 surprisingly outperformed GPT-4o in Baba Is AI, a puzzle game about manipulating game world rules, scoring 44 percent compared to GPT-4o's 34 percent. In TextWorld's text-based puzzles, GPT-4o and Claude 3.5 Sonnet both achieved just over 40 percent, while other models scored below 20 percent.
The results turned particularly grim in NetHack, a complex game requiring long-term planning and adaptation. No model achieved more than 1.5 percent progress. Similarly, in MiniHack's combat and exploration tasks, all models failed completely when tested without prior training.
GPT-4o the strongest model to date
The models performed even worse when processing visual information compared to text-only input. The study reveals serious shortcomings in visual decision-making, the research team noted. The models had major problems when they have to make decisions based on visual information.
The researchers emphasize these results highlight crucial gaps in current AI capabilities, particularly in applying abstract knowledge to specific situations — but also could guide future research directions.
The current list of best models can be viewed on the BALROG project page.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.