Allen AI claims its new Tülu 3 405B open source model rivals top performers like Deepseek V3
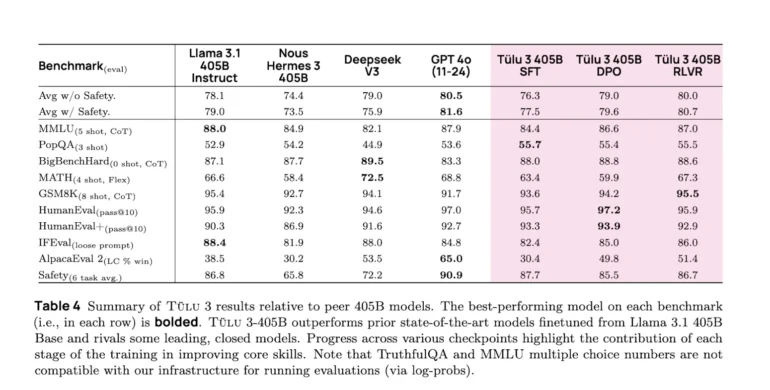
The Allen Institute for AI has released Tülu 3 405B, an open source language model that reportedly matches or exceeds the performance of DeepSeek V3 and GPT-4o. The team credits much of this success to a new training approach called RLVR.
Built on Llama 3.1, the model uses "Reinforcement Learning with Verifiable Rewards" (RLVR), which only rewards the system when it produces verifiably correct answers. This approach works particularly well for mathematical tasks where results can be easily checked, according to AI2.
Training the 405 billion-parameter model pushed technical limits, requiring 32 compute nodes with 256 GPUs working together. Each training step took 35 minutes, and the team had to use workarounds like a smaller helper model to manage the computational demands. The project faced ongoing technical hurdles that needed constant attention - insights rarely shared by companies developing similar models.
Significant performance improvements demonstrated
AI2 says Tülu outperforms other open source models like Llama 3.1 405B Instruct and Nous Hermes 3 405B, despite having to end training early due to computing constraints. It also matches or exceeds the performance of DeepSeek V3 and GPT-4o. The training process combined Supervised Finetuning, Direct Preference Optimization, and RLVR - an approach that shows similarities to Deepseek's R1 training, particularly in how according to the team reinforcement learning benefited larger models more.
Users can test the model in the AI2 Playground, with code available on GitHub and models on Hugging Face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.