OpenAI's largest model GPT-4.5 is now available for ChatGPT Plus

Updated March 5, 2025:
GPT-4.5 is now available for all ChatGPT Plus users.
Originally posted February 28, 2025:
OpenAI's largest model GPT-4.5 delivers on vibes instead of benchmarks
OpenAI has released GPT-4.5 as a "Research Preview". The new language model is intended to be more natural and less hallucinatory, but is significantly more expensive than its predecessors.
OpenAI has released GPT-4.5 as a "research preview," describing it as their largest and best model for chat. The new model is initially available to ChatGPT Pro users and developers, with Plus and Team users gaining access next week.
GPT-4.5 represents an evolution of "unsupervised learning" rather than following the "reasoning" approach of the o1 series. While models like o1 and o3-mini think before responding through reasoning, GPT-4.5 answers directly as a classic large language model, achieving its performance improvements through traditional pre-training scaling.
According to OpenAI, GPT-4.5 (also known as Orion) is the company's largest model to date and, according to OpenAI researcher Rapha Gontijo Lopes the company "(probably) trained the largest model in the world." At the same time, the company emphasizes in its system card that GPT-4.5 is not a "frontier model." This likely stems from the fact that the company has trained o3, a model that significantly outperforms GPT-4.5 in many areas.
The price reflects the computational demands: At $75 per million input tokens and $150 per million output tokens, GPT-4.5 is significantly more expensive than GPT-4o ($2.50/$10) or o1 ($15/$60). The team is therefore uncertain whether the model will be offered through the API in this form long-term. Like its predecessor, it has a context length of 128,000 tokens.
OpenAI believes reasoning will be a core capability of future models and that the two scaling approaches – pretraining and reasoning – will complement each other. As models like GPT-4.5 become more intelligent and knowledge-intensive through pretraining, they provide stronger foundations for reasoning and tool-based agents. Altman announced several weeks ago that GPT-5 will combine these two capabilities.
GPT-4.5 shows mixed performance results
In benchmark tests, GPT-4.5 shows significant improvements in some areas: In the SimpleQA test, it achieves an accuracy of 62.5% compared to 38.2% for GPT-4o or 43.6% for the recently released Grok 3.
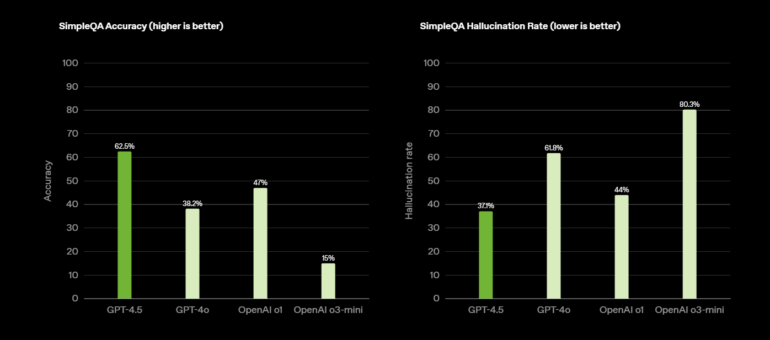
The hallucination rate drops from 61.8% to 37.1%, outperforming both o1 and o3-mini. In MMMLU (multilingual) and MMMU (multimodal), it surpasses its predecessors GPT-4o (81.5% and 69.1%) and o3-mini (81.1% and NN) with scores of 85.1% and 74.4%, respectively.
In human evaluation tests, testers preferred GPT-4.5 over GPT-4o in all categories: creative intelligence (56.8%), professional questions (63.2%), and everyday questions (57.0%).
However, in STEM benchmarks, it cannot beat reasoning models like o3-mini: In GPQA (natural sciences), it reaches 71.4% compared to 53.6% for GPT-4o, but falls behind OpenAI o3-mini (79.7%). In AIME '24 (mathematics), GPT-4.5 achieves 36.7%, a significant improvement over GPT-4o (9.3%), but doesn't come close to o3-mini (87.3%). For coding tasks, GPT-4.5 performs better in the SWE-Lancer Diamond Test with 32.6% compared to GPT-4o (23.3%) and outperforms o3-mini (10.8%) – albeit at significantly higher costs. In the SWE-Bench Verified Test, it reaches 38.0% compared to 30.7% for GPT-4o, but lags behind o3-mini (61.0%).
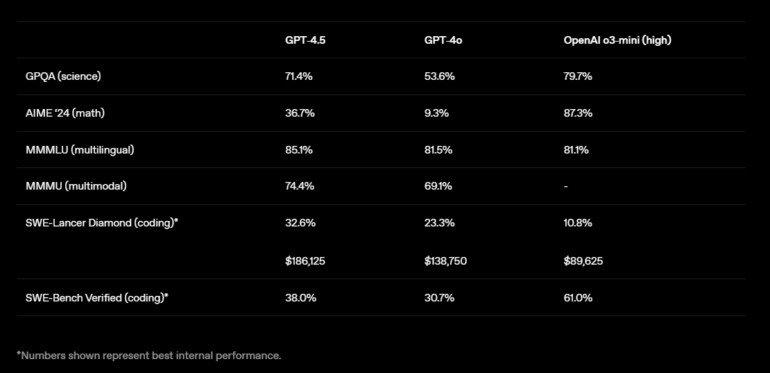
The recently released Claude 3.7 Sonnet achieves 62.3% and 70.3% respectively in the benchmarks published by Anthropic. However, these values aren't directly comparable since different methods and problem sets were used or tested. Case in point: In the system card for o3-mini, the model still reached 49.3%.
In the independent Aider Polyglot Coding Benchmark, GPT-4.5 achieves 45%, significantly more than GPT-4o's 23%, but still trails behind other models. Sonnet 3.7 reaches 60% without "thinking."
In short: There's no massive performance leap reflected in benchmarks – the best results are probably found in the SimpleQA test. In the coming days, there will likely be much discussion about whether scaling is dead, whether deep learning is hitting a wall, and when reasoning might meet the same fate.
GPT-4.5: Vibes and diffuse improvements
OpenAI CEO Sam Altman, who recently became a father, was not present at the GPT-4.5 presentation but commented on X: "It is the first model that feels like talking to a thoughtful person to me. i have had several moments where i've sat back in my chair and been astonished at getting actually good advice from an AI." Altman emphasizes that GPT-4.5 is not a reasoning model and won't break benchmark records: "It’s a different kind of intelligence and there’s a magic to it i haven’t felt before."
More about vibes than benchmarks, then.
Founding member and former employee Andrej Karpathy sees similar progress, though he finds it difficult to measure. In his comments on the release, he explains that each 0.5 step in the version number represents roughly a tenfold increase in training compute.
Karpathy describes the evolution of GPT models: From GPT-1, which barely generated coherent text, to GPT-2 as a "confused toy," to GPT-3, which delivered significantly more interesting results. GPT-3.5 then crossed the threshold to market readiness and triggered OpenAI's "ChatGPT moment."
With GPT-4, the improvements were already more subtle, according to Karpathy. "Everything was just a little bit better but in a diffuse way," he writes. Word choice was somewhat more creative, understanding of prompt nuances improved, analogies made a bit more sense, the model was slightly funnier, and hallucinations occurred somewhat less frequently.
He tested GPT-4.5 with similar expectations, a model developed with ten times the training compute of GPT-4. His conclusion: "I'm in the same hackathon 2 years ago. Everything is a little bit better and it's awesome, but also not exactly in ways that are trivial to point to."
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.