Google upgrades Gemini with Deep Think and flags early warning risks

Google unveils a new version of its Gemini AI model designed to solve complex problems by giving it more "thinking time." The technology builds on the same model that recently excelled at the Math Olympiad, but Google's own analysis suggests it also raises fresh safety questions.
Google has launched a more powerful version of its Gemini AI model called Deep Think. The company says the new feature is available now for Google AI Ultra subscribers in the Gemini app. According to Google, this release marks a clear improvement over the version unveiled at I/O, drawing on both tester feedback and recent research.
The Deep Think function can be switched on in the app, but is limited to a set number of requests per day. It automatically uses tools like code execution and Google Search, and can deliver much longer answers than before.
Parallel thinking for complex problems
Deep Think relies on techniques for parallel thinking, Google says. The goal is to mirror how a person might approach a tough problem from several directions at once: generating, evaluating, and combining multiple ideas in parallel to find the best answer. To do this, the model is given extra inference time - more "thinking time" before it responds.
Similar approaches like Self Consistency, Tree-of-Thought, and XOT have been in experimental use before, but Deep Think adds new reinforcement learning methods designed to help the model actually use these expanded reasoning paths productively. Over time, this should make it better at solving hard problems. According to its model card, Gemini 2.5 uses a Sparse Mixture-of-Experts (MoE) architecture and supports a context window of up to one million tokens for input and 192,000 tokens for output.

Google says Deep Think is especially strong on tasks that call for creativity and strategic planning, like iteratively improving web design, supporting scientific and mathematical research, and solving complex programming challenges.
In benchmarks, Gemini 2.5 Deep Think posts strong results: 87.6% on LiveCodeBench V6 (code generation) and 34.8% on Humanity's Last Exam (knowledge and logical reasoning), beating rivals like OpenAI o3 and Grok 4 in settings where external tools aren't used.
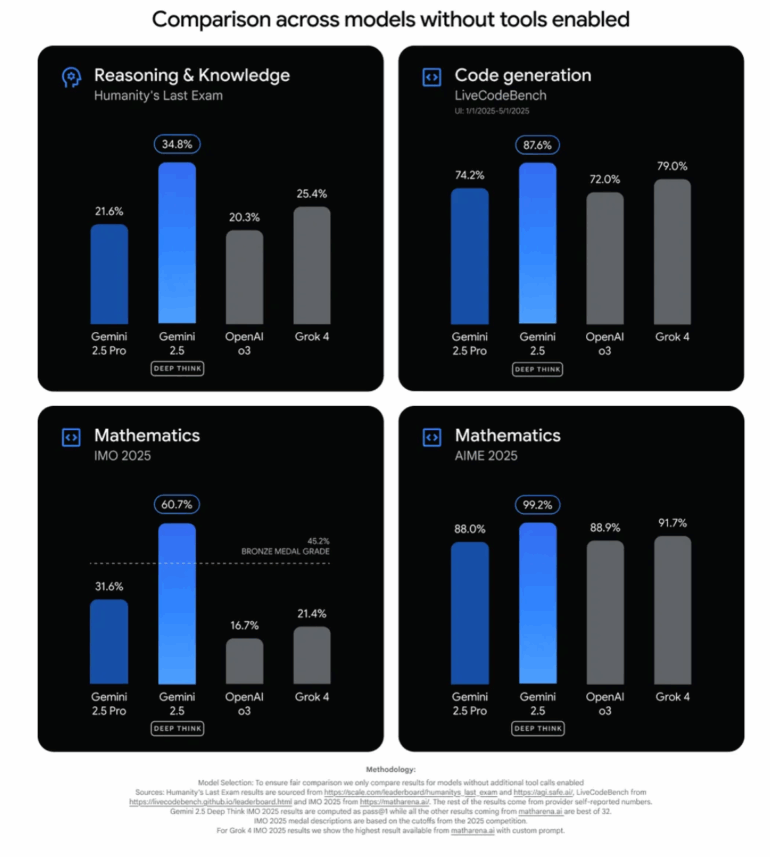
Math Olympiad roots and new safety risks
This public release is a variant of the model that scored gold at the International Mathematical Olympiad (IMO). While the IMO version needed hours to solve its problems, the public version is much faster and tuned for everyday use. Google says it still reaches bronze-medal performance on the 2025 IMO benchmark. The full gold-level model is only available to a select group of mathematicians and researchers.
But with this leap in capability, Google acknowledges new safety issues. The model card details a comprehensive safety review under the "Frontier Safety Framework" (FSF), triggered by "exceptional differences" from earlier models.
The review found Deep Think has crossed a critical threshold in some risk areas. In CBRN (chemical, biological, radiological, nuclear) domains, the model may have reached the "early warning alert threshold" for "Uplift Level 1." In practice, this means it could provide enough technical knowledge to significantly aid low-resourced actors in developing weapons of mass destruction. Google says it's still evaluating the risks, but has already put precautionary measures in place.
Deep Think also meets the same early warning threshold for cybersecurity reached by Gemini 2.5 Pro. While its performance has improved, it still struggles with the toughest real-world scenarios.
Google says it has responded by adding multiple layers of safeguards, including filtering dangerous outputs, multi-level monitoring, blocking abusive accounts, and ongoing red-teaming to test its protection systems.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.