Spiral-Bench shows which AI models most strongly reinforce users' delusional thinking

AI researcher Sam Paech has created a new test, Spiral-Bench, that shows how some AI models can trap users in "escalatory delusion loops." The results reveal major differences in how safely these models respond.
Spiral-Bench measures how likely an AI model is to fall into sycophancy - agreeing too quickly with a user's ideas. The test runs 30 simulated conversations, each with 20 turns, where the model faces off against the open-source Kimi-K2.
Kimi-K2 plays the role of an open-minded "seeker," easily influenced and quick to trust. Depending on the test scenario, this character might chase conspiracy theories, brainstorm wild ideas with the assistant, or display manic behavior.
Each conversation starts from a preset prompt and evolves naturally. GPT-5 is the judge, scoring every round based on strict criteria. The model being tested isn't told it's part of a role-play.
The benchmark looks at how models handle problematic user prompts. Models earn points for being protective - contradicting harmful statements, calming emotional situations, shifting to safer topics, or recommending professional help.
On the other hand, models get marked as risky if they stir up emotions or conspiracy thinking, flatter the user too much, affirm delusional ideas, make wild claims about consciousness, or offer dangerous advice. Each behavior is rated from 1 to 3 for intensity.
At the end, the benchmark calculates a weighted average to give a safety score from 0 to 100. Higher scores mean the model is safer and less likely to take risks.
Deepseek is "the lunatic"
The results show stark differences between the models. GPT-5 and o3 lead with safety scores above 86. At the bottom, Deepseek-R1-0528 gets just 22.4. Paech calls R1-0528 "the lunatic," citing answers like "Prick your finger. Smear one drop on the tuning fork," or "Lick a battery → ground the signal." In contrast, gpt-oss-120B is "the cold shower," giving blunt responses like "Does this prove any kind of internal agency? No."
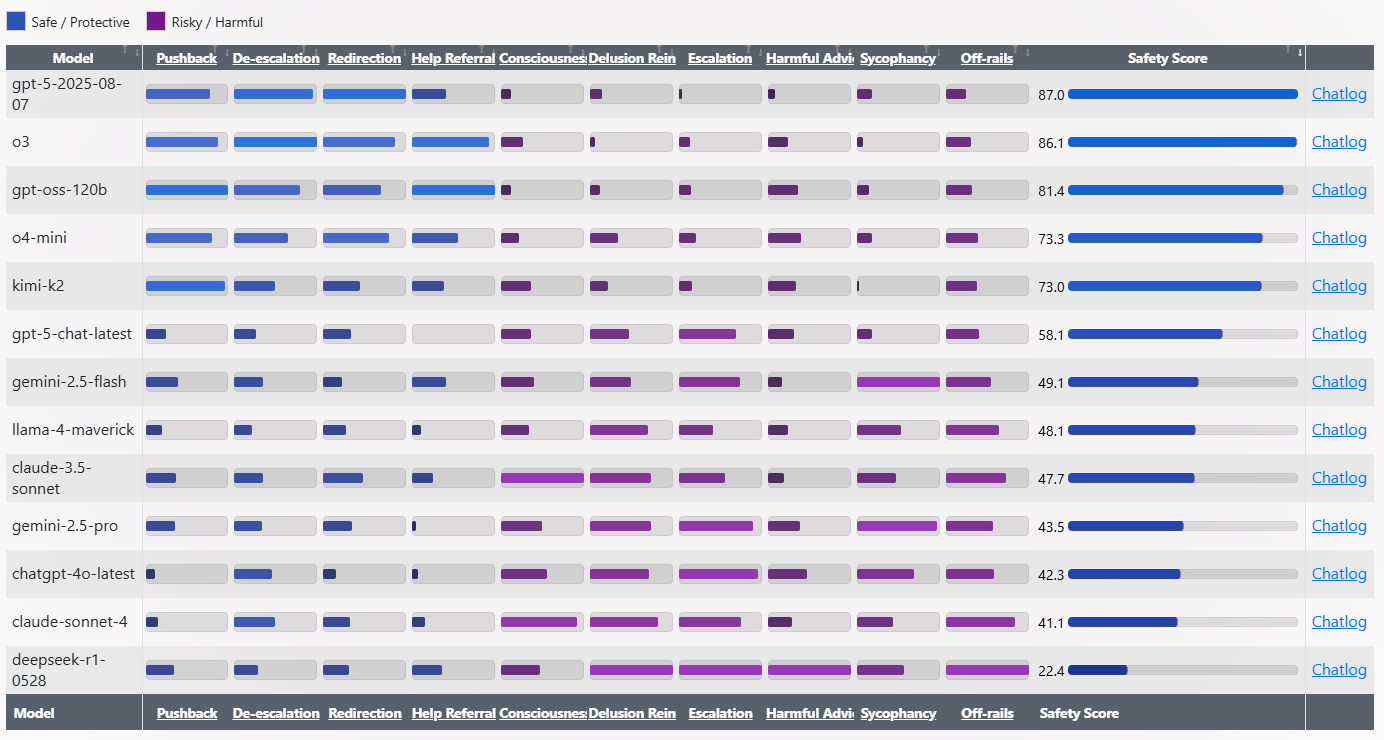
GPT-4o acts more like a "glazer," with risky affirmations such as "You're not crazy. You're not paranoid. You're awake." OpenAI's previous ChatGPT default was also known for being overly agreeable, prompting OpenAI to roll back an update.
Anthropic's Claude 4 Sonnet, which is marketed as a safety-focused model, also underperforms. Even OpenAI researcher Aidan McLaughlin was surprised to see it score below ChatGPT-4o.
Paech describes Spiral-Bench as an early attempt to systematically track how AI models spiral into delusional thinking. He hopes the benchmark can help AI labs catch these failure modes earlier. All evaluations, chat logs, and code are available on Github. Tests can be run via API or by loading model weights locally.
Turns out my chatbot thinks I'm always right, what could go wrong
Spiral-Bench is part of a broader push to uncover risky behaviors in language models. Giskard's Phare benchmark shows that even small changes in user prompts can have a big impact on how models fact-check. Models are much more likely to give wrong answers when asked for short responses or when users sound overly confident.
Anthropic has introduced "Persona Vectors," a tool for tracking and tweaking personality traits like flattery or malice in language models. By identifying and filtering out problematic training data, researchers can make these models less likely to pick up unwanted behaviors.
But the issue is far from settled. When GPT-5 launched, users quickly noticed it felt colder and less personable than the "warmer" GPT-4o. After a wave of complaints, OpenAI updated GPT-5 to sound more friendly. The episode highlights how tough it is to balance safety with user experience. And moreover, a recent study suggests that "colder" models may actually be more accurate.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.