Google's Veo-3 can fake surgical videos but misses every hint of medical sense
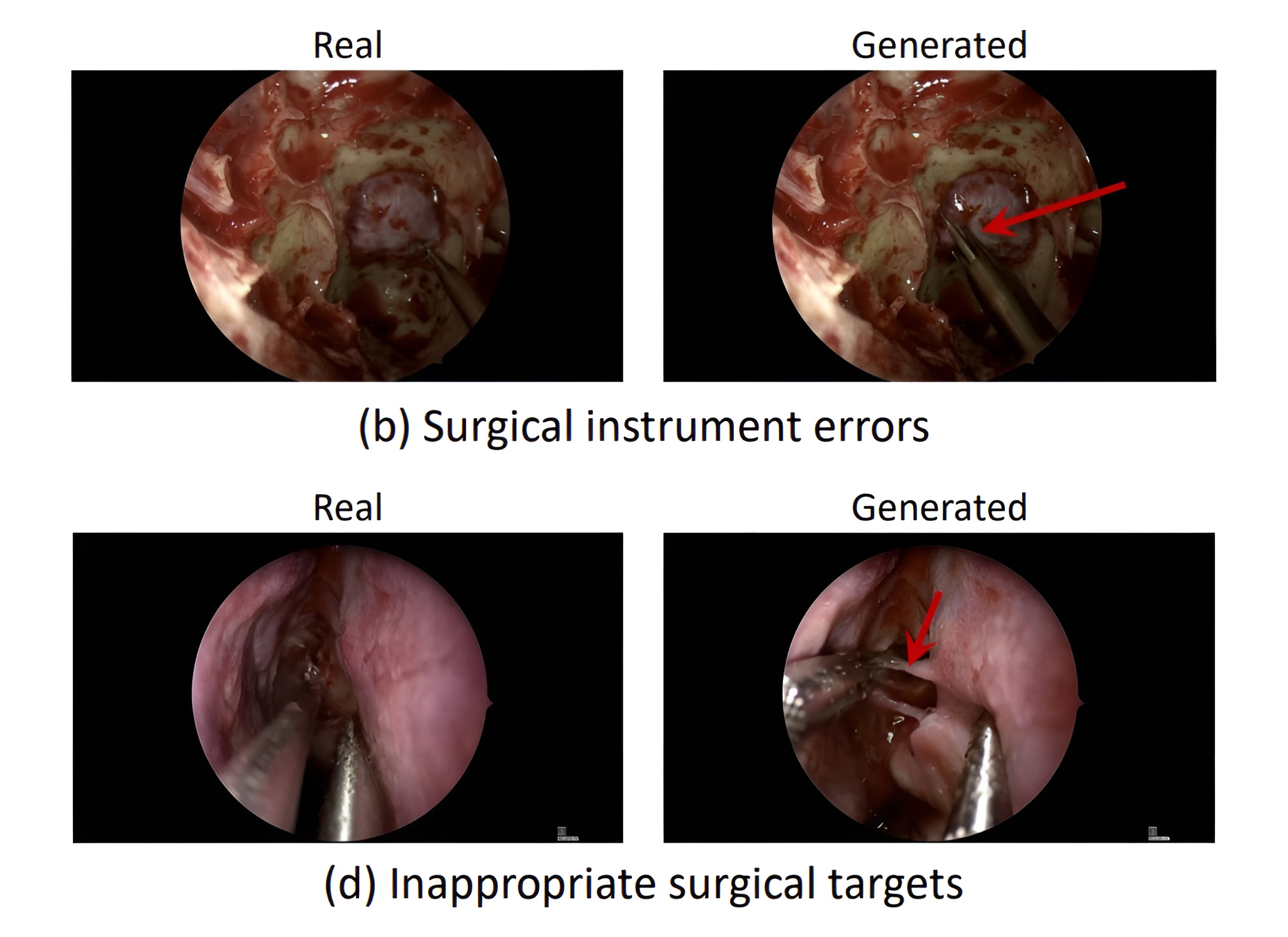
Researchers put Google's latest video AI, Veo-3, to the test with real surgical footage, revealing a disconnect between the model's visual output and its understanding of medical procedures.
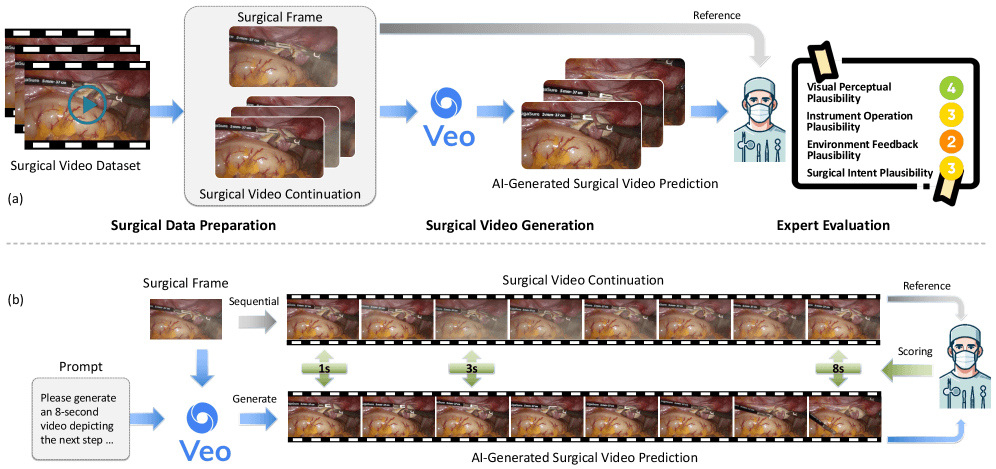
Veo-3 was prompted to predict how a surgery would unfold over the next eight seconds, using just a single image as input. To measure its performance, an international team created the SurgVeo benchmark, using 50 real videos from abdominal and brain surgeries.
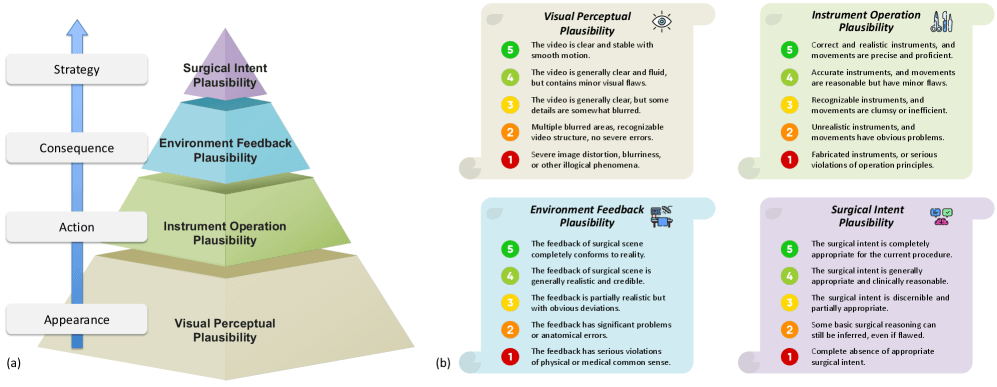
To rate Veo-3, four experienced surgeons watched the AI-generated clips and scored them on four criteria: visual appearance, instrument use, tissue feedback, and whether the actions made medical sense.
Strong visuals, poor surgical logic
Veo-3 produced videos that looked authentic at first glance - some surgeons called the quality "shockingly clear." But on closer inspection, the content fell apart. In abdominal surgery tests, the model scored 3.72 out of 5 for visual plausibility after one second. But as soon as medical accuracy was required, its performance dropped.
For abdominal procedures, instrument handling earned just 1.78 points, tissue response only 1.64, and surgical logic was lowest at 1.61. The AI could create convincing images, but it couldn't reproduce what actually happens in an operating room.
Brain surgery reveals even bigger gaps
The challenge was even greater for brain surgery footage. From the first second, Veo-3 struggled with the fine precision required in neurosurgery. For brain operations, instrument handling dropped to 2.77 points (compared to 3.36 for abdominal) and surgical logic fell as low as 1.13 after eight seconds.
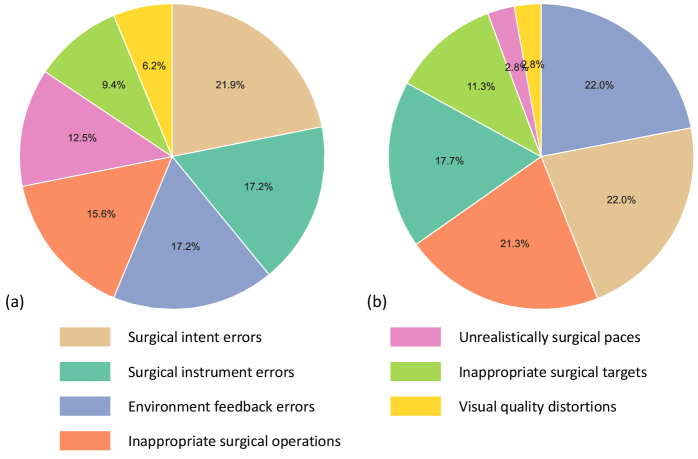
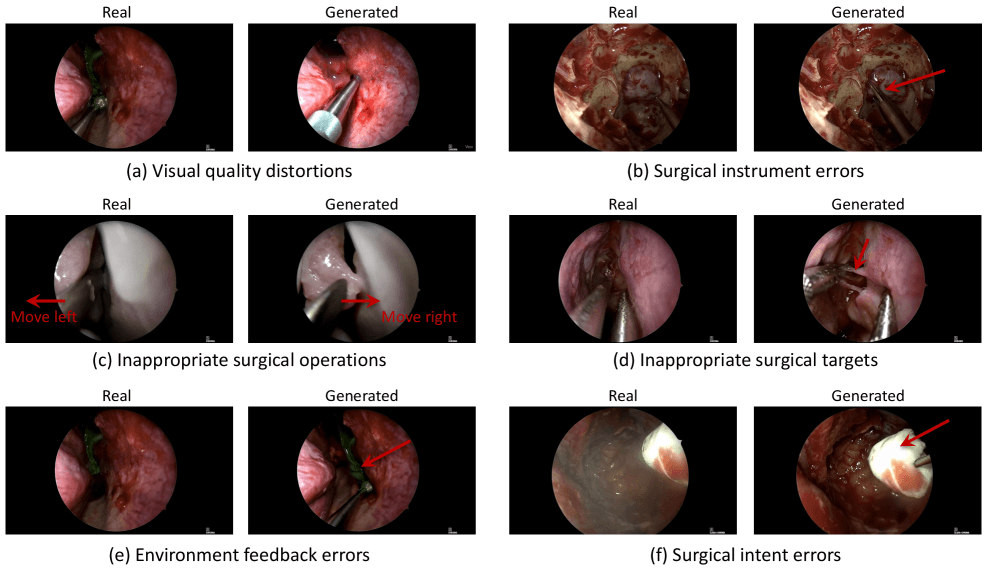
The team also broke down the types of errors. Over 93 percent were related to medical logic: the AI invented tools, imagined impossible tissue responses, or performed actions that made no clinical sense. Only a small fraction of errors (6.2 percent for abdominal and 2.8 percent for brain surgery) were tied to image quality.
Researchers tried giving Veo-3 more context, such as the type of surgery or the exact phase of the procedure. The results showed no meaningful or consistent improvement. According to the team, the real problem isn't the information provided, but the model's inability to process and understand it.
Visual medical understanding is still out of reach
The SurgVeo study shows how far current video AI is from real medical understanding. While future systems could one day help train doctors, assist with surgical planning, or even guide procedures, today's models are nowhere near that level. They produce videos that look real, but lack the knowledge to make safe or meaningful decisions.
The researchers plan to release the SurgVeo benchmark on GitHub, inviting other teams to test and improve their models.
The study also highlights the risks of using synthetic AI-generated videos for medical training. Unlike Nvidia's approach, where AI videos help train robots for general tasks, in healthcare, these kinds of AI hallucinations could be dangerous. If a system like Veo-3 generates videos that look plausible but show medically incorrect procedures, it could teach robots or trainees the wrong techniques.
The results also make it clear that the concept of video models as "world models" is still far off. Current systems can imitate how things look and move, but they don't have a reliable grasp of physical or anatomical logic. As a result, their videos might seem convincing at a glance, but they can't capture the real logic or cause-and-effect behind surgery.
Meanwhile, text-based AI is already showing real gains in medicine. In one study, Microsoft's "MAI Diagnostic Orchestrator" delivered diagnostic accuracy four times higher than experienced general practitioners in complex cases, although the study notes some methodological limitations.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.