New study maps how AI models think and where their reasoning breaks down
A large analysis of more than 170,000 reasoning traces from open-source reasoning models shows that large language models rely heavily on simple, default strategies when tasks get harder. A new cognitive science framework for categorizing thinking processes makes it easier to see which abilities are missing and when extra reasoning guidance in the prompt actually helps.
According to the study "Cognitive Foundations for Reasoning and Their Manifestation in LLMs", current tests for language models don’t really measure their reasoning abilities. They focus mainly on whether the final answer is correct, the authors write. Whether a model is genuinely reasoning or simply repeating familiar patterns usually remains hidden.
To get around this, the team analyzed 171,485 detailed reasoning traces from 17 models and compared them with 54 think‑aloud solution paths produced by humans. The tasks covered everything from math problems and error detection to political and medical dilemmas.

Mapping the cognitive building blocks behind model reasoning
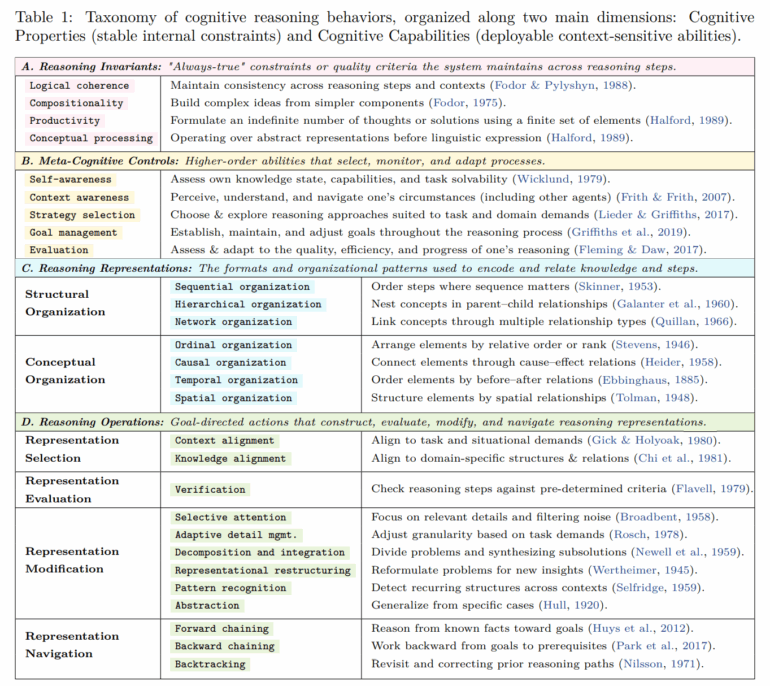
To compare these traces, the researchers defined 28 recurring thinking components. These include:
- Basic rules like consistency and combining simple concepts into more complex ones.
- Self‑management behaviors such as setting goals, noticing uncertainty, or checking progress.
- Different ways of organizing information - as a list, tree, causal chain, or spatial image.
- Typical reasoning moves such as breaking problems into parts, checking intermediate steps, rolling back a faulty approach, or generalizing from examples.
They used this framework to annotate each portion of a reasoning trace where one of these components appeared.
When tasks get messy, AI models shift into autopilot
The results show a clear pattern. On well-structured tasks, such as classic math problems, models use a relatively diverse set of thinking components. But as tasks become more ambiguous - like open‑ended case analyses or moral dilemmas - the models narrow their behavior. Linear step‑by‑step processing takes over, along with simple plausibility checks and forward reasoning from the given facts.
A statistical analysis shows that successful solutions on these difficult tasks correlate with the opposite behavior: more structural variety, hierarchical organization, building causal networks, reasoning backward from the goal, and intentional reframing. These patterns appear far more often in the human traces. Humans describe their approach, evaluate intermediate results, and switch flexibly between strategies and representations.
The examples documented in the paper make this contrast tangible. In a logical checkerboard problem, a human solves the task with a short argument based on an abstraction of the color layout. A DeepSeek‑R1 trace for the same problem runs more than 7,000 tokens, listing coordinates one by one, bouncing between hypotheses, and repeatedly attempting verification before eventually arriving at an abstraction.
In an open‑ended health care reform design task, a human participant explicitly breaks the problem into subgoals, names their strategy, evaluates sources by credibility, focuses on relevant information, organizes health systems by criteria, abstracts a composite assessment, and ends by noting that the outcome is surprising. The corresponding DeepSeek‑R1 trace also uses problem decomposition and causal reasoning but shows very few explicit strategy shifts, self‑reflection moments, or representation changes.

Across all tasks, the pattern is consistent: humans use more metacognition and abstraction, switching flexibly between representations, while LLMs tend to generate long, repetitive, linear reasoning chains.
Whether these findings apply to proprietary reasoning models from companies like OpenAI remains unclear. The authors note that open models depend heavily on automatically generated reasoning traces during training, which may push them into a kind of sequential autopilot. Whether proprietary models trained more intensively on human reasoning data behave differently is an open question the study does not answer.
Guided reasoning only helps strong models
The team also tested whether the most successful reasoning patterns could be turned into practical prompts. From common success structures, they derived instructions that prescribe a thinking process - for example, selecting relevant information first, then building a structure, and only afterward drawing conclusions.
Models like Qwen3‑14B, Qwen3‑32B, R1‑Distill‑Qwen‑14B/32B, R1‑Distill‑Llama‑70B, and Qwen3‑8B showed clear accuracy gains, in some cases more than 20 percent relative improvement. On dilemmas and case analysis tasks, accuracy increased by up to 60 percent in specific scenarios. Complex, poorly structured categories like Dilemma, Diagnosis‑Solution, and Case Analysis benefited the most.
For smaller or weaker models, the effect sometimes reversed. Hermes‑3‑Llama‑3‑8B and DeepScaleR‑1.5B saw double‑digit relative drops on average and lost up to 70 percent accuracy on some well‑structured tasks. R1‑Distill‑Qwen‑7B and OpenThinker‑32B reacted inconsistently, with gains in some categories and losses in others.
The authors conclude there appears to be a capability threshold: only models with sufficiently strong reasoning and instruction‑following skills can make good use of detailed cognitive scaffolding. The results also suggest that extra structure hints are less useful on well‑structured problems and may conflict with learned heuristics. Whether this guidance unlocks latent abilities or mainly optimizes the retrieval of trained patterns remains unclear.
Why the research community focuses on what is easy to measure
A meta‑analysis of 1,598 arXiv papers shows that LLM reasoning research has largely concentrated on easy‑to‑measure behaviors like step‑by‑step explanations and problem decomposition. Metacognition and spatial or temporal organization rarely receive attention - even though the empirical reasoning‑trace analysis suggests they are critical for difficult, poorly structured tasks.
Overall, the researchers argue that the field still relies on a narrow, linear decomposition framework that overlooks many significant cognitive phenomena.
What this means for the next generation of reasoning models
The authors highlight several challenges and opportunities based on their findings.
First, there is no existing theory linking training methods to the cognitive abilities that emerge. Cognitive psychology suggests that procedural skills develop through repetition, but metacognition requires explicit reflection on one's thinking. Applied to LLMs, this could mean that standard RL setups strengthen verification but do little for self‑monitoring or strategy shifts.
Second, the study shows that while LLMs perform well on clear tasks like story problems or factual queries, they struggle with similar tasks that are less structured, such as design or diagnostic problems. In cognitive science, flexible reasoning requires learning abstract rules from many different task types. The authors propose training LLMs on structurally diverse datasets and teaching them to compare task formats.
Third, they warn that model‑generated solution steps do not necessarily reveal whether the model truly understands the problem or is simply reusing patterns. Testing this requires evaluations that measure whether a model can transfer knowledge to new situations, along with deeper analyses of how model internals operate.
Fourth, the researchers see their cognitive map as a tool for shaping training more deliberately. For example, reinforcement learning rewards could be adjusted to encourage rare but important reasoning styles like reframing or metacognition.
The team plans to release its code and data on GitHub and Hugging Face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.