OpenAI's new ChatGPT image model matches Google's Nano Banana Pro on complex prompts

Key Points
- OpenAI has released GPT Image 1.5, a new image generation model for ChatGPT that delivers faster results and follows prompts more accurately than its predecessor.
- The model handles complex instructions more reliably, such as correctly rendering a 6×6 grid with 36 different objects, while maintaining consistency in lighting, composition, and character appearance during image editing.
- API prices have dropped by 20 percent despite the performance improvements, with OpenAI positioning the model for marketing and e-commerce use cases due to its improved ability to preserve brand logos and visual elements.
OpenAI says the new GPT-Image 1.5 model follows prompts more accurately, preserves details better, and generates images significantly faster.
OpenAI says the new GPT-Image 1.5 model brings several major improvements: more accurate prompt interpretation, better detail preservation, and significantly faster generation times.
The new model generates images up to four times faster than before, and users can queue up new images while others are still processing. The model is now live for all ChatGPT users and through the API.
OpenAI's app CEO Fidji Simo sees the new image generation as part of a bigger shift: ChatGPT is moving from a reactive, text-based tool toward a "fully generative UI that brings in the right components based on what you want to do."
Edits stay more consistent across lighting, composition, and faces
The model also handles image editing differently now. It makes targeted changes without messing up other parts of the image, keeping lighting, composition, and faces more consistent compared to its predecessor. OpenAI says it can handle adding, removing, combining, blending, and transposing image elements.
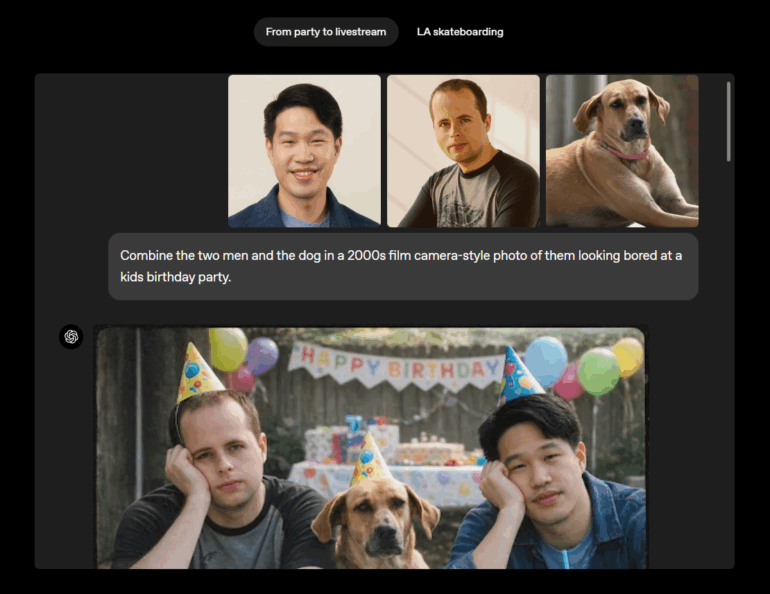
Use cases include photo editing, virtual try-ons for clothes and hairstyles, and style transformations. OpenAI's demos show things like combining multiple people and a dog from separate photos into one scene, or turning a photo into a movie poster with a golden age Hollywood look.
The model actually follows complex prompts now
The new model is noticeably better at following detailed instructions. In a test with a 6 x 6 grid that needed specific objects in each cell, the new version got the arrangement right, while the old one didn't, OpenAI says. This makes it easier to create images where the placement of elements really matters.

Text rendering is noticeably improved as well. The model can now handle denser, smaller text—so you can get legible snippets of articles, short tables, or infographics with numbers. However, OpenAI admits it still struggles with longer stretches of text, unusual fonts, multiple faces in one image, or producing content in different languages.
We ran our benchmark prompt that requires a detailed, complex, photorealistic scene with an unusual element: a horse riding an astronaut, something the models definitely haven't seen during training. Older models choked on this. But the latest generation, including Flux 2, does much better. The new Image-1.5 performs on par with Google's Nano Banana Pro, and far better than the previous version.



First impressions: the ChatGPT image model produces more intense-looking images compared to Google's Nano Banana Pro. With the same prompt, Nano Banana Pro interprets things more literally and produces a casual photo look rather than a polished photoshoot vibe. That said, this could be a prompting thing.


API prices drop 20 percent despite better performance
Developers can access the model as GPT Image 1.5 through the API. OpenAI says image inputs and outputs are 20 percent cheaper than the previous model. Pricing sits at 8 dollars per million input tokens and 32 dollars per million output tokens for images. Text tokens cost 5 dollars (input) and 10 dollars (output) per million tokens. With the predecessor model GPT-1, images ran between 0.02 cents and 0.19 cents per image depending on quality settings.
OpenAI says the model does a better job preserving brand logos and visual elements, which could matter for marketing and e-commerce use cases. The previous version of ChatGPT image generation is still available as a custom GPT.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now