Metas "LLaMA" language model shows that parameters are not everything

Meta introduces the LLaMA language models, which with relatively few parameters can outperform much larger language models such as GPT-3.
Meta's AI research department releases four foundational models ranging from 7 to 65 billion parameters. The 13-billion-parameter LLaMA (Large Language Model Meta AI) is said to outperform Meta's open-source OPT model and GPT-3's 175-billion-parameter GPT-3 on "most" language tasks.
More data for better results
The largest LLaMA model, with 65 billion parameters, is said to be able to compete with Google's massive Palm model with 540 billion parameters, and is on par with Deepmind's Chinchilla, according to the researchers.

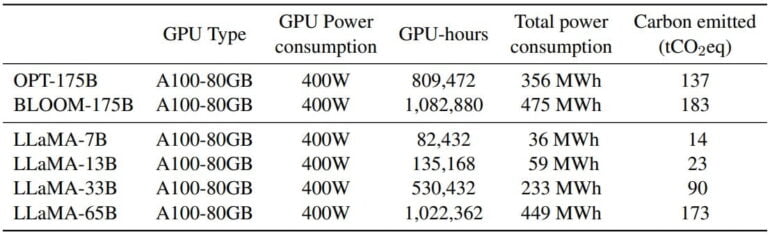
The LLaMA model requires a similar amount of training hours, and thus consumes a similar amount of CO₂, as the 175 Billion models OPT and Bloom. However, its operational cost is lower (see below).
The comparison with Chinchilla is interesting in that Deepmind then, like Meta now, adopted a new training approach with LLaMA, based on a larger number of training data (tokens) than usual. LLaMA is Meta's Chinchilla, so to speak, and the researchers explicitly cite the model as an inspiration.
All our models were trained on at least 1T tokens, much more than what is typically used at this scale.
Interestingly, even after 1T tokens the 7B model was still improving.
3/n pic.twitter.com/qiXieIAKC6- Guillaume Lample (@GuillaumeLample) February 24, 2023
LLaMA shows that training with more data is reflected in performance. Training is pricier and time consuming, but the model is more efficient later.
The objective of the scaling laws from Hoffmann et al. (2022) is to determine how to best scale the dataset and model sizes for a particular training compute budget. However, this objective disregards the inference budget, which becomes critical when serving a language model at scale. In this context, given a target level of performance, the preferred model is not the fastest to train but the fastest at inference, and although it may be cheaper to train a large model to reach a certain level of performance, a smaller one trained longer will ultimately be cheaper at inference.
From the paper
LLaMA's 13-billion model, which operates at the GPT-3 level, runs on a single Nvidia Tesla V100 graphics card, according to the Meta research team. It could help democratize access to and research on large-scale language models.
The LLaMA language models also show that larger models can still have significant performance reserves if a company pays the bills and combines large models with even more data. Meta's research team plans to do this in the future, as well as fine-tune the models with instructions.
We plan to release larger models trained on larger pretraining corpora in the future, since we have seen a constant improvement in performance as we were scaling.
From the paper
Public data for AI training
LLaMA differs from Deepmind's Chinchilla and other large language models in its training data, according to the Meta Research team. LLaMA uses only publicly available data, while other models use undocumented or non-public datasets for training.
Much (67%) of LLaMA's data comes from a cleaned version of the widely used English Common Crawl dataset. Other data sources include public GitHub and Wikipedia. The LLaMA models are therefore "compatible with open-sourcing," the team writes.
This is questionable, at least to the extent that common open-source licenses do not yet provide for their use in AI training, and the models typically do not cite sources in their output. Even if large companies are currently doing so, it is unlikely that effective consent to use data for AI training can be inferred from the public availability of data on the Internet alone. Going forward, the courts may help clarify this.
Meta releases the language models under the non-commercial GPL v3 license to selected partners in academia, government and industry. Interested parties can apply here. Access to the model card and instructions for use are available on Github.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.