Video AI models hit a reasoning ceiling that more training data alone won't fix, researchers say

Key Points
- An international consortium of 32 institutions has published the Very Big Video Reasoning Suite, the largest dataset for visual reasoning in videos to date.
- Even top video models like Sora 2 and Veo 3.1 only hit about half of human performance on the benchmark.
- The researchers point to a lack of controllability as a core problem: models arbitrarily change scene elements during video generation, making logical reasoning unreliable.
An international research team has released the largest dataset for video reasoning to date, roughly a thousand times bigger than previous alternatives. The results show that even Sora 2 and Veo 3.1 fall far behind humans when it comes to reasoning tasks.
Whether a video model can solve a puzzle, predict a physical trajectory, or sort objects by rules has barely been studied in any systematic way. The field simply lacked large enough datasets, and previous benchmarks mostly included test data but nothing to actually train on.
A consortium of more than 50 researchers from 32 institutions—including UC Berkeley, Stanford, Harvard, and the University of Oxford—wants to change that. Their Very Big Video Reasoning (VBVR) suite includes over two million images and around one million video clips spread across 200 curated tasks. Nine existing benchmarks contribute roughly 12,800 samples. On top of test data, VBVR also provides one million training examples for the first time.
The tasks follow a taxonomy grounded in theories of human cognition, stretching from Aristotle's cognitive abilities to Kant's categories of the mind. The researchers break them into five groups: abstraction, knowledge, perception, spatiality, and transformation. Each category runs on a parameterized task generator that can produce thousands of different instances. Every task must have a unique solution and can't be solved from a single still image.

Sora 2 reaches roughly half of human performance
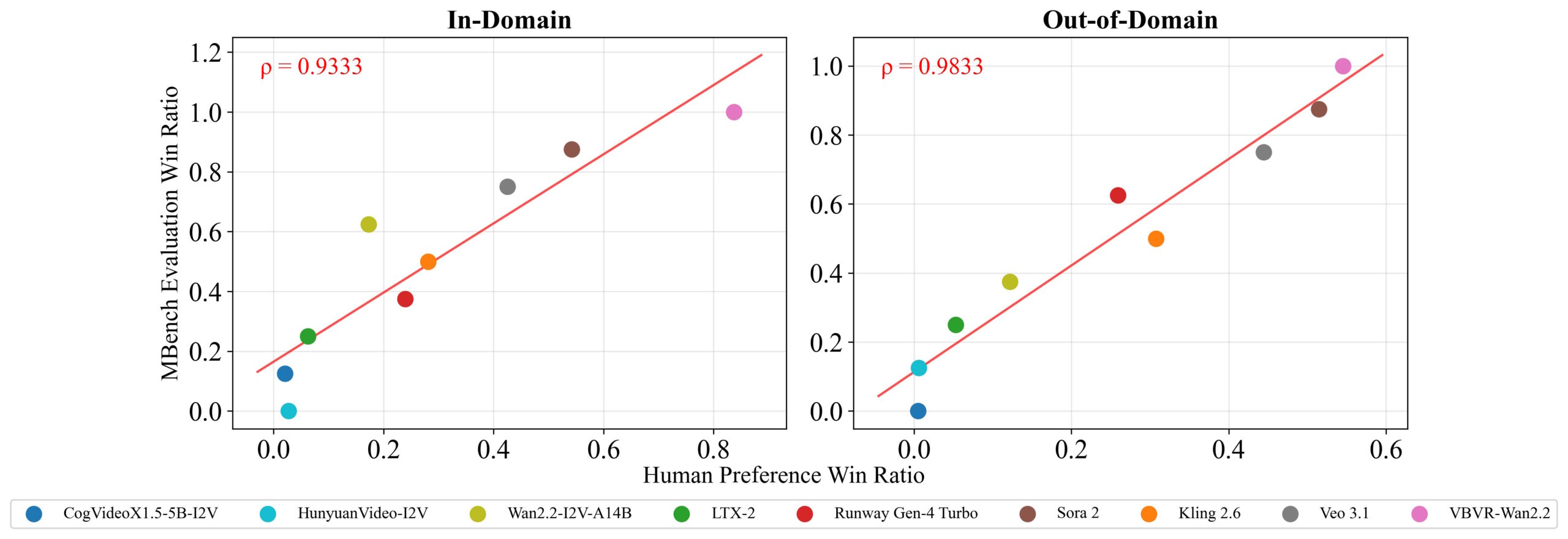
The VBVR-Bench results aren't pretty. Humans score 0.974 overall. OpenAI's Sora 2, the top proprietary model in the study, manages just 0.546. Google Deepmind's Veo 3.1 follows at 0.480, Runway Gen-4 Turbo lands at 0.403, and Kuaishou's Kling 2.6 comes in at 0.369. The open-source models Wan2.2, CogVideoX, HunyuanVideo, and LTX-2 range between 0.273 and 0.371.
VBVR-Bench deliberately skips using a language model as a judge. Since most tasks have a single correct answer, rule-based scores measure spatial precision, path correctness, and logical validity directly. The researchers verified that these automatic scores reliably reflect actual quality by checking them against human judgments, which showed very high statistical agreement.
Fine-tuned open-source model beats every proprietary system
The most striking finding comes from VBVR-Wan2.2, a fine-tuned version of Wan2.2. Its overall score jumps to 0.685, an 84.6 percent improvement over the base model, beating every proprietary system in the lineup.
The scaling study tells a more complicated story, though. Performance on familiar task types climbs to 0.771 with around 400,000 training examples and then hits a wall. On entirely new task types, it tops out at 0.610, still 15 percentage points behind. The researchers see this as a fundamental bottleneck in current video generation architectures, suggesting that throwing more data at the problem won't fix it.

Models can't reason if they can't follow instructions
A qualitative analysis comparing VBVR-Wan2.2 directly with Sora 2 leads to a key insight: if a model freely rewrites a scene during generation—swapping out backgrounds, layouts, or object identities—intermediate states become unreliable, and any reasoning built on them falls apart.
In a deletion task, for instance, Sora 2 makes unnecessary rearrangements after removing the target object, while VBVR-Wan2.2 executes only what was asked. In a rotation task, Sora 2 can't tell the difference between the target region and the object it's supposed to manipulate. VBVR-Wan2.2 even picks up emergent capabilities beyond its training, like consistent completion strategies for symmetry tasks. Still, flickering and duplication crop up in longer sequences.
Cognitive skills don't develop evenly across models
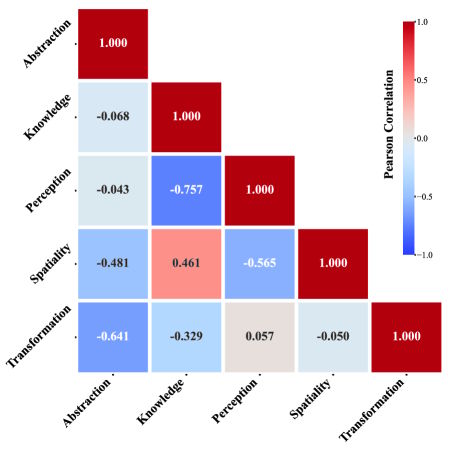
A correlation analysis across all models turns up some interesting patterns. Models that do well on knowledge tasks also tend to be strong on spatial tasks, which lines up with neuroscience research on the hippocampus and its dual role in navigation and conceptual learning.
The flip side is less intuitive: strong knowledge performance actually correlates with weakness in perception. Abstraction doesn't correlate positively with any other ability, but models that excel at abstraction tasks actually tend to be weaker at transformation and spatial reasoning.
The full dataset, benchmark toolkit, and models are publicly available at video-reason.com. The researchers stress that architectural advances like state tracking and self-correction mechanisms will be needed to push past the performance ceiling they've identified.
Back in September 2025, a study involving Google Deepmind suggested that Google's Veo 3 video model has surprisingly versatile zero-shot capabilities: it can solve mazes, spot symmetries, and simulate physical relationships without any task-specific training. The researchers took this as an early sign that video models could become universal foundations for machine vision, much like large language models already serve as the backbone for text processing. Some, including Deepmind CEO Demis Hassabis, believe video models could eventually form the basis for world models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now