Meta's new LIMA language model reaches GPT-4 level

With LIMA, Meta's AI researchers introduce a new language model that achieves GPT-4 and Bard level performance in test scenarios, albeit fine-tuned with relatively few examples.
LIMA stands for "Less is More for Alignment," and the name hints at the model's function: It is intended to show that with an extensively pre-trained AI model, a few examples are sufficient to achieve high-quality results.
Few examples in this case means that Meta manually selected 1,000 diverse prompts and their output from sources such as other research papers, WikiHow, StackExchange, and Reddit.
The team then used these examples to refine its own 65-billion-parameter LLaMA model, the leaked language model that sparked the open-source language model movement. Meta avoided the expensive RLHF, which OpenAI uses to tune its models and sees as an important part of the future of AI.
Style over substance
Meta had humans compare the results of LIMA and other models, including GPT-4, text-davinci-003, and Google Bard. According to Meta, human evaluators preferred LIMA's answers to GPT-4's 43 percent of the time across 200 examples, with LIMA outperforming Google Bard 58 percent of the time and text-davinci-003 65 percent of the time. All of these models, except LIMA, were refined with human feedback.
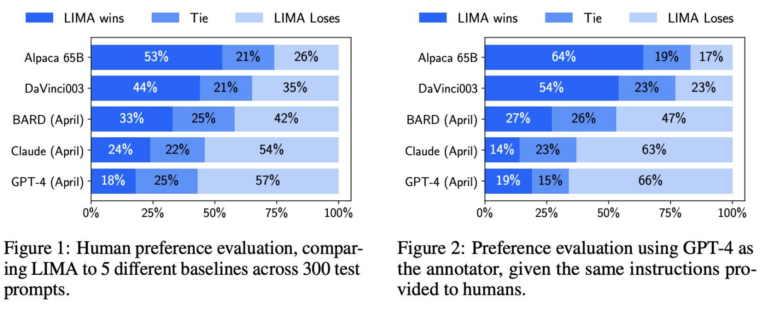
The Meta research team suggests that these results indicate that a language model acquires much of its knowledge through pre-training, and that rather limited fine-tuning with a few examples is sufficient to teach models to generate high-quality content.
As a result, the extensive human feedback training used by OpenAI may not be as important as previously thought. A point that Meta clearly makes in its research paper.
The "Superficial Alignment Hypothesis"
Meta defines this finding as the "superficial alignment hypothesis". It says that the so-called alignment phase after pre-training is primarily about teaching the model a certain style or format that it can recall when interacting with users.
Thus, fine-tuning is more about style than substance. This would be in contrast to the common practice of particularly extensive and complex fine-tuning processes, such as OpenAI's RLHF.
Meta's research team sees two limitations to LIMA: First, building datasets with high-quality examples is a challenging approach that is difficult to scale. Second, LIMA is not as robust as models that are already available as products, such as GPT-4.
LIMA generates mostly good answers, the team says, but an "adversarial prompt" or an "unlucky sample" could lead to weak answers. Still, Lima shows that the complex problem of aligning and fine-tuning an AI model can be solved with a simple approach, Meta's team says.
Meta's head of AI research, Yann LeCun, takes a pragmatic view of this relative devaluation of the effort behind GPT-4 and similar models: He sees large language models as an element of the near future that will not play a role in the medium term, at least not "without significant changes".
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.