AI2 releases Dolma, the largest open-source dataset for LLMs

The Allen Institute for AI (AI2) has unveiled Dolma, an open-source dataset of three trillion tokens from a diverse collection of web content, scientific publications, code, and books. It is the largest publicly available dataset of its kind to date.
Dolma is the foundation of the Open Language Model (OLMo), currently under development at AI2 and scheduled for release in early 2024. With the goal of developing the "best open language model" in mind, the massive Dolma (Data to feed OLMo) dataset was created.
Dolma is currently the largest open-source dataset and is now available to developers and researchers through Hugging Face. There you will also find the tools that the researchers used to create it, to ensure the reproducibility of the results.
Dolma is mostly English data
To create Dolma, data from various sources was converted into clean text documents.
In the first version, Dolma is largely limited to English texts. A language recognition model was used to filter the data. To compensate for a bias toward minority dialects, the team included all texts that the model classified as English with 50 percent confidence. Future versions will include other languages.

In subsequent steps, the researchers cleaned the dataset of duplicates, low-quality content, or sensitive information, and improved the quality of the code examples.
Comparison with other open datasets
Much of the data comes from the non-profit Common Crawl project, which focuses on web data. In addition, there are other web pages from the C4 collection, academic texts from peS20, code snippets from The Stack, books from Project Gutenberg, and the English Wikipedia.
The ideal dataset, in the eyes of AI21, should meet several criteria: Openness, representativeness, size, and reproducibility. It should also minimize risks, especially those that could affect individuals.
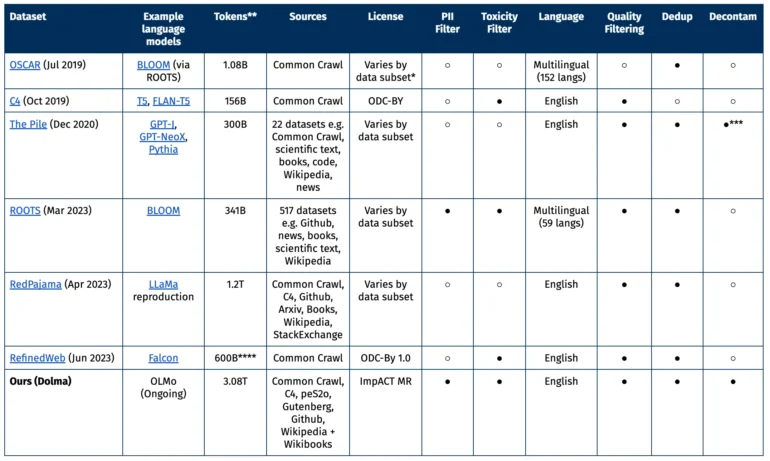
Previous studies have shown that not only the number of parameters in the model, but also the amount of training material in a language model plays a central role in performance.
Dolma availability and the question of open-source
The dataset is released under AI2's ImpACT license as a medium-risk artifact. Researchers must meet certain requirements, such as providing their contact information and agreeing to the intended use of Dolma. In addition, a mechanism has been established to allow the removal of personal data upon request.
The license has too many weird clauses to be counted as open-source.
— Narendra Patwardhan (@overlordayn) August 20, 2023
After Dolma was released as an open-source dataset, some critics argued that there were too many clauses in the license. In their eyes, Dolma is open, but could not be considered open-source. Meta's designation of the LLaMA-2 model as open-source was also recently criticized by the Open Source Initiative.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.