StableVideo lets you edit video with Stable Diffusion
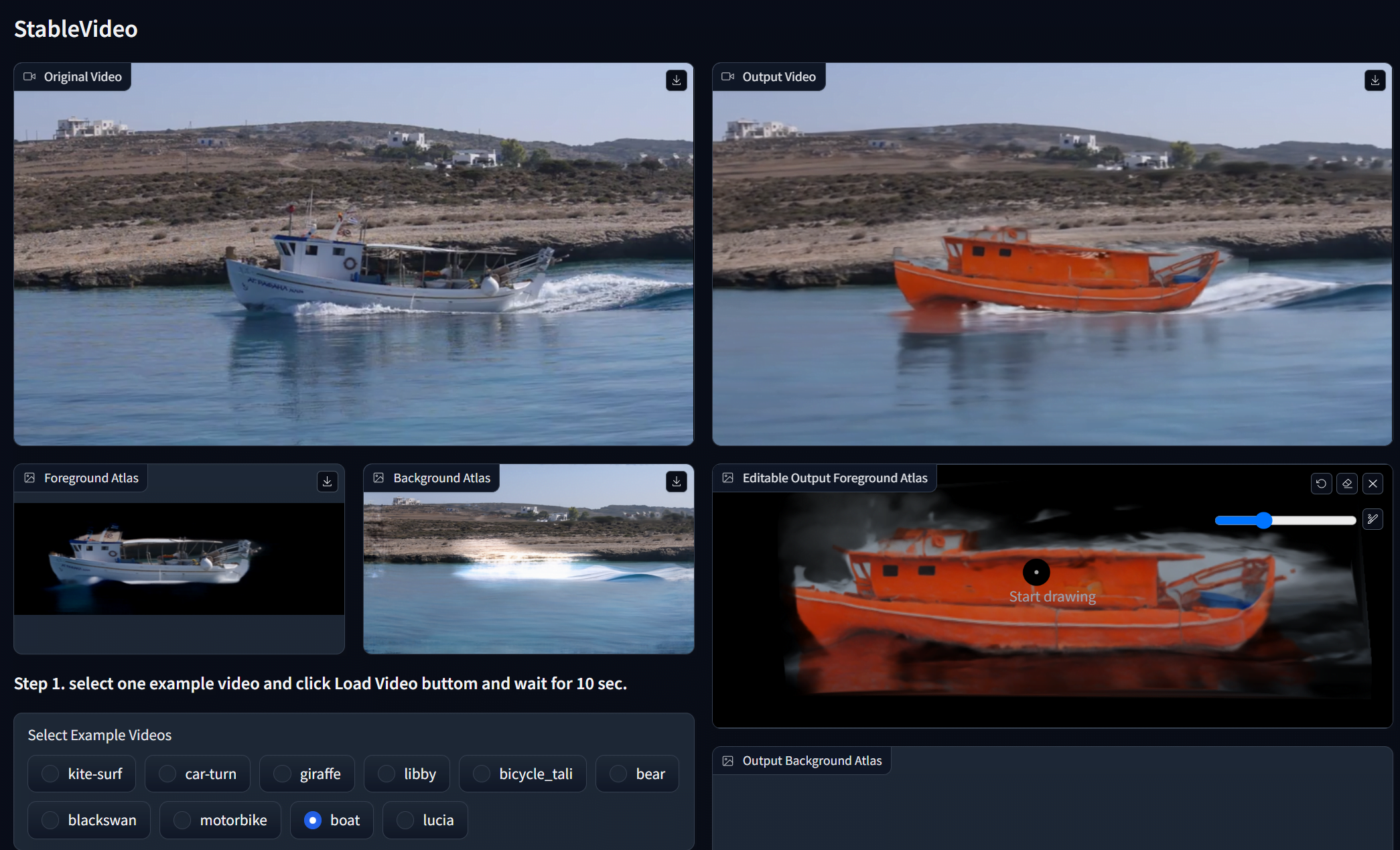
StableVideo brings some video editing capabilities to Stable Diffusion, such as allowing style transitions or changing backgrounds.
Generating realistic and temporally coherent videos from text prompts remains a challenge for AI systems, with even state-of-the-art systems such as those from RunwayML still showing significant inconsistencies.
While there is still much work to be done on this frontier, some research, such as StableVideo, is exploring how generative AI can build on existing videos. Instead of generating videos from scratch, StableVideo uses diffusion models such as Stable Diffusion to edit videos frame by frame.
According to the researchers, this ensures consistency across frames through a technique that transfers information between key frames. This allows objects and backgrounds to be modified semantically while maintaining continuity, similar to VideoControlNet.
StableVideo introduces inter-frame propagation for better consistency
It does this by introducing "inter-frame propagation" to diffusion models. This propagates object appearances between keyframes, allowing for consistent generation across the video sequence.
Specifically, StableVideo first selects key frames and uses a standard diffusion model such as Stable Diffusion to process them based on text prompts. The model takes visual structure into account to preserve shapes. It then transfers information from one edited keyframe to the next using their common overlap in the video. This guides the model to generate subsequent frames consistently.
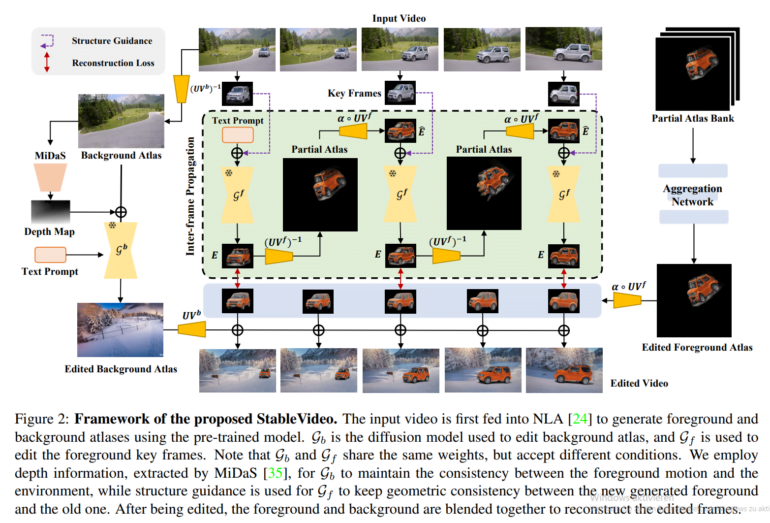
Finally, an aggregation step combines the edited keyframes to create edited foreground and background video layers. Compositing these layers produces the final, coherent result.
Video: Chai et al.
Video: Chai et al.
In experiments, the team demonstrates StableVideo's ability to perform various text-based edits, such as changing object attributes or applying artistic styles, while maintaining strong visual continuity throughout.
However, there are limitations: performance still depends on the capabilities of the underlying diffusion model, according to the researchers. Consistency also fails for complex deforming objects, which requires further research.
More information and the code is available on the StableVideo GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.