Agent skills look great in benchmarks but fall apart under realistic conditions, researchers find
AI agents are supposed to tap into specialized knowledge through so-called skills. A study testing 34,000 real-world skills now shows these enhancements barely help under realistic conditions, and weaker models actually perform worse with them.
Anthropic first introduced skills in October 2025 as a modular system for Claude Code, where the agent automatically figures out which specialized instructions it needs for a given task. Other platforms like OpenAI's Codex and a range of open-source projects quickly picked up the concept.
Skills are structured text files that encode domain-specific knowledge, things like workflows, API usage patterns, and best practices. Agentic AI systems can pull up these files while working on a task and apply the procedures they describe. The big question is, how useful are skills when agents have to find and apply them on their own?
Existing benchmarks paint an overly rosy picture
A new study by researchers from UC Santa Barbara, MIT CSAIL, and the MIT-IBM Watson AI Lab delivers a sobering answer: the benefits of skills are "fragile" and shrink drastically once test conditions get more realistic. In the most demanding scenarios, results barely beat the no-skill baseline.
The problem, the researchers say, is how skills have been tested so far. The existing benchmark SKILLSBENCH hands agents hand-curated, task-specific skills directly—essentially giving them a step-by-step walkthrough for the task at hand.
One example from the study makes this clear: a task requires identifying flood days at USGS gauging stations. The three provided skills contain the exact API for downloading water level data, the specific URL for flood thresholds, and ready-made code snippets for spotting flood days. "These skills combined almost directly spell out the exact solution guide for the task," the researchers write.

In the real world, though, agents don't get ready-made skills and have no guarantee that suitable skills even exist. They have to dig through large, noisy collections on their own and adapt general-purpose skills to specific tasks.
34,000 real skills put to the test
For their study, the researchers pulled together 34,198 real skills from open source repositories, filtered by permissive licenses (MIT and Apache 2.0) and deduplicated. The skills come from the aggregation platforms skillhub.club and skills.sh and cover everything from web development to data engineering and scientific computing.
From there, the team tested six progressively more realistic scenarios: from handing over curated skills directly, to throwing in distractors, to having the agent search the entire collection on its own, both with and without curated skills in the pool.
Three models got put through their paces: Claude Opus 4.6 with Claude Code, Kimi K2.5 with Terminus-2, and Qwen3.5-397B-A17B with Qwen Code. Each model ran the entire pipeline independently, including skill retrieval and task solving.
Performance drops steadily as conditions get more realistic
The results show consistent degradation across all models. Claude Opus 4.6 hit a pass rate of 55.4 percent when curated skills were force-loaded. Once the agent had to pick which skills to load on its own, the rate dropped to 51.2 percent. Adding distractors knocked it down to 43.5 percent, independent search brought it to 40.1 percent, and removing curated skills from the pool left it at 38.4 percent. The no-skill baseline sat at 35.4 percent.
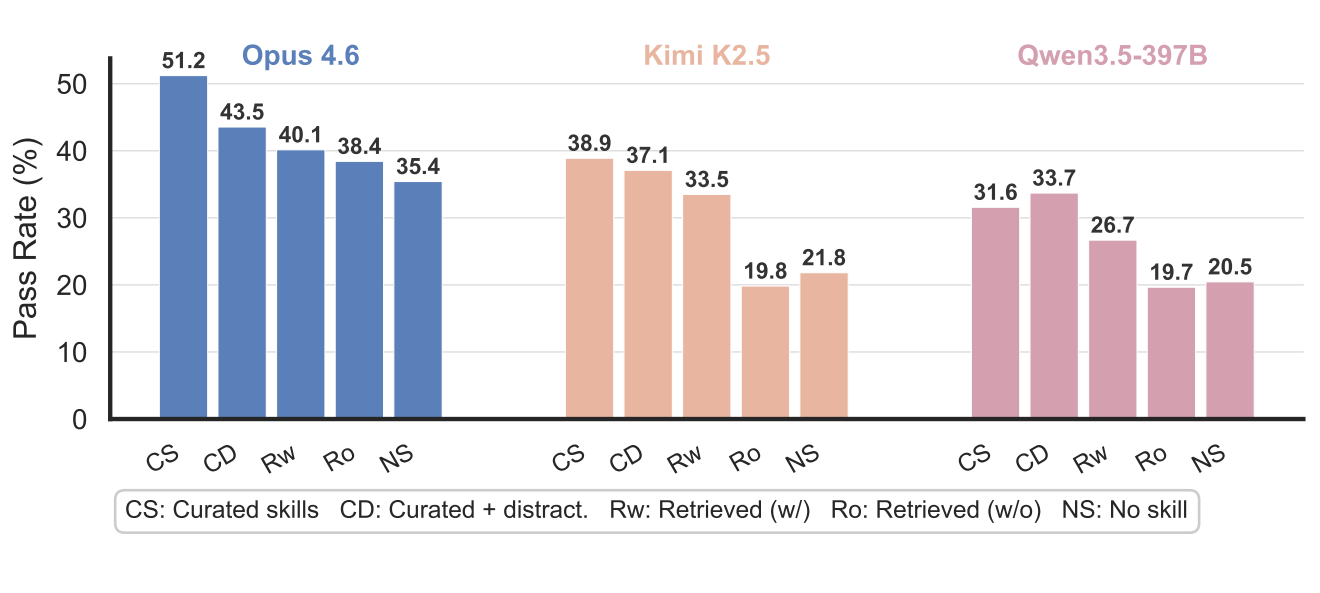
The picture gets worse for weaker models. Kimi K2.5 fell to 19.8 percent in the most realistic scenario - actually below its own no-skill baseline of 21.8 percent. Qwen3.5-397B showed the same pattern, landing at 19.7 percent versus 20.5 percent without skills. Irrelevant skills can actively throw weaker models off track by burning resources on loading and following useless instructions.
Agents struggle with selection, search, and adaptation
The researchers pinpoint three key bottlenecks. First, agents already choke at the selection stage: even when curated skills are right there, only 49 percent of Claude runs load all of them. Toss in distractors, and that drops to 31 percent. Kimi, interestingly, shows much higher loading rates—86 percent in the curated setting—which the researchers chalk up to differences in the agent environment. But Kimi's eagerness to load skills doesn't translate into better task performance.
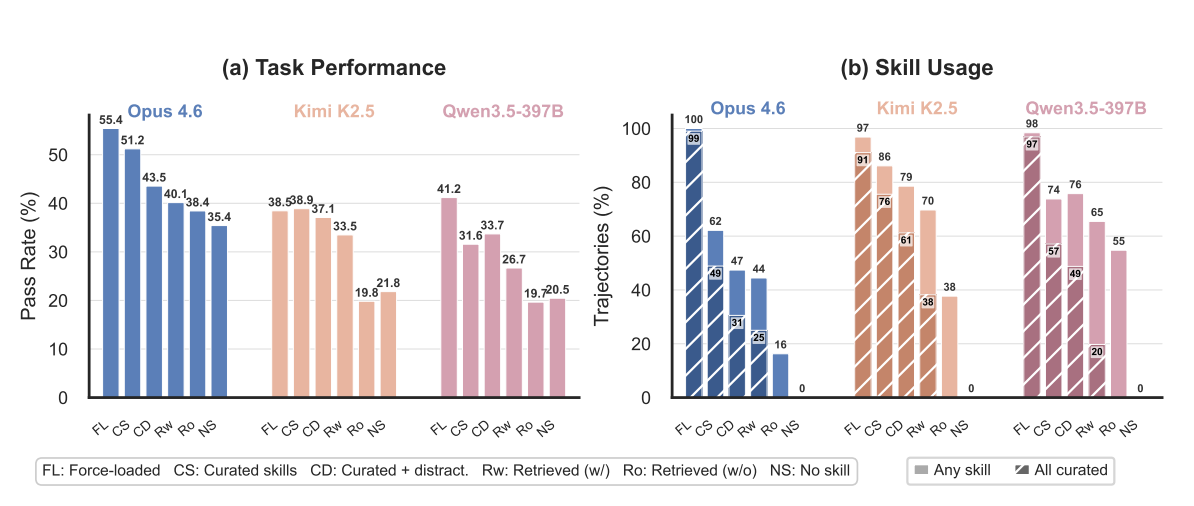
Second, independent search makes things worse, since even the best retrieval method only hits 65.5 percent Recall@5. Third, agents can't adapt general skills to specific tasks when no tailored skills exist.
For skill search itself, the researchers compared several retrieval strategies. The winner was an "agentic hybrid search," where the agent iteratively writes search queries, checks candidates, and tweaks its strategy. This beat a simple semantic search by 18.7 percentage points at Recall@3.
Refinement helps, but only when the starting material is solid
To close the performance gap, the researchers tested two refinement strategies. In task-specific refinement, the agent explores the task, takes a first crack at a solution, evaluates how useful the retrieved skills were, and builds new, tailored skills from that process. In a tensor parallelism task, for example, the agent combined ideas from two different skills to create a new one that neither original offered on its own.
The numbers tell the story: Claude climbed from 40.1 to 48.2 percent on SKILLSBENCH. On the general agent benchmark Terminal-Bench 2.0, task-specific refinement pushed Claude from 61.4 to 65.5 percent. The jump from 57.7 to 65.5 percent captures the combined effect of skill retrieval and refinement against the no-skill baseline.
Task-independent refinement, where skills get improved offline without knowledge of the target task, delivered only spotty improvements. The researchers conclude that refinement works more as a multiplier of existing skill quality than as a source of new knowledge. It mainly helps when the initially retrieved skills already contain relevant information.
Earlier testing already flagged problems with the skill approach
These findings line up with an earlier study by Vercel that uncovered a fundamental flaw in the skill approach: in 56 percent of test cases, the agent simply never retrieved the available skill. The pass rate with skills matched the no-documentation baseline exactly. A simple Markdown file (AGENTS.md) passively loaded into the agent's context, on the other hand, achieved a perfect 100 percent pass rate, while the skill system topped out at 79 percent.
The current study confirms this core problem systematically across multiple models and at a much larger scale: agents frequently don't recognize available skills as relevant and just skip them entirely.
The research team is calling for better retrieval methods, more effective offline refinement strategies, and skill ecosystems that account for varying model capabilities. The study's code is available on GitHub.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.