Reliable AI systems for medicine need high-quality data. But such data is still rare. A new model could get around the problem.
Artificial intelligence for medical diagnostics promises to improve patient care. This would be particularly helpful in areas where specialists are scarce and waiting times are long. The first systems for diagnostic image analysis have already been approved.
But the development of AI systems requires so-called "labeled data" from human experts, such as X-ray images of the lungs on which suspicious and identified cancerous tissue is already marked so that it can be read by computers. This training data is still rare and expensive because - unlike other use cases of AI image analysis - only designated experts can process the data.
AI in medicine: Pre-trained models learn faster
One possible solution is to use masses of unlabeled data to pre-train AI models - supervised by experts - and then specialize them for their task using the limited data available. During AI training, the models learn patterns present in the data, which can then be used with supervised training.
This approach has been used successfully for some time in speech systems such as GPT-3. The approach has also now proven successful in image analysis. In mid-2020, an AI system from Google pre-trained with three billion images cracked the best values in the ImageNet benchmark.
Researchers have now presented pre-trained models for diagnostic systems. One AI model was trained with almost 105 million images of various anatomies (head, abdomen, chest, legs, etc.).
The images are composed of computed tomography (CT) scans, magnetic resonance imaging (MRI) scans, X-rays, and ultrasound scans. In addition, none of the data sets were labeled. A second model was also trained with approximately 24500 3D brain images.
Depending on the AI model, the training took up to two weeks on four server nodes, each with eight 16-gigabyte Nvidia Volta GPUs, 80 CPU cores, and 512 gigabytes of memory. The team also experimented with different architectures.
With 100 million images to the best AI system
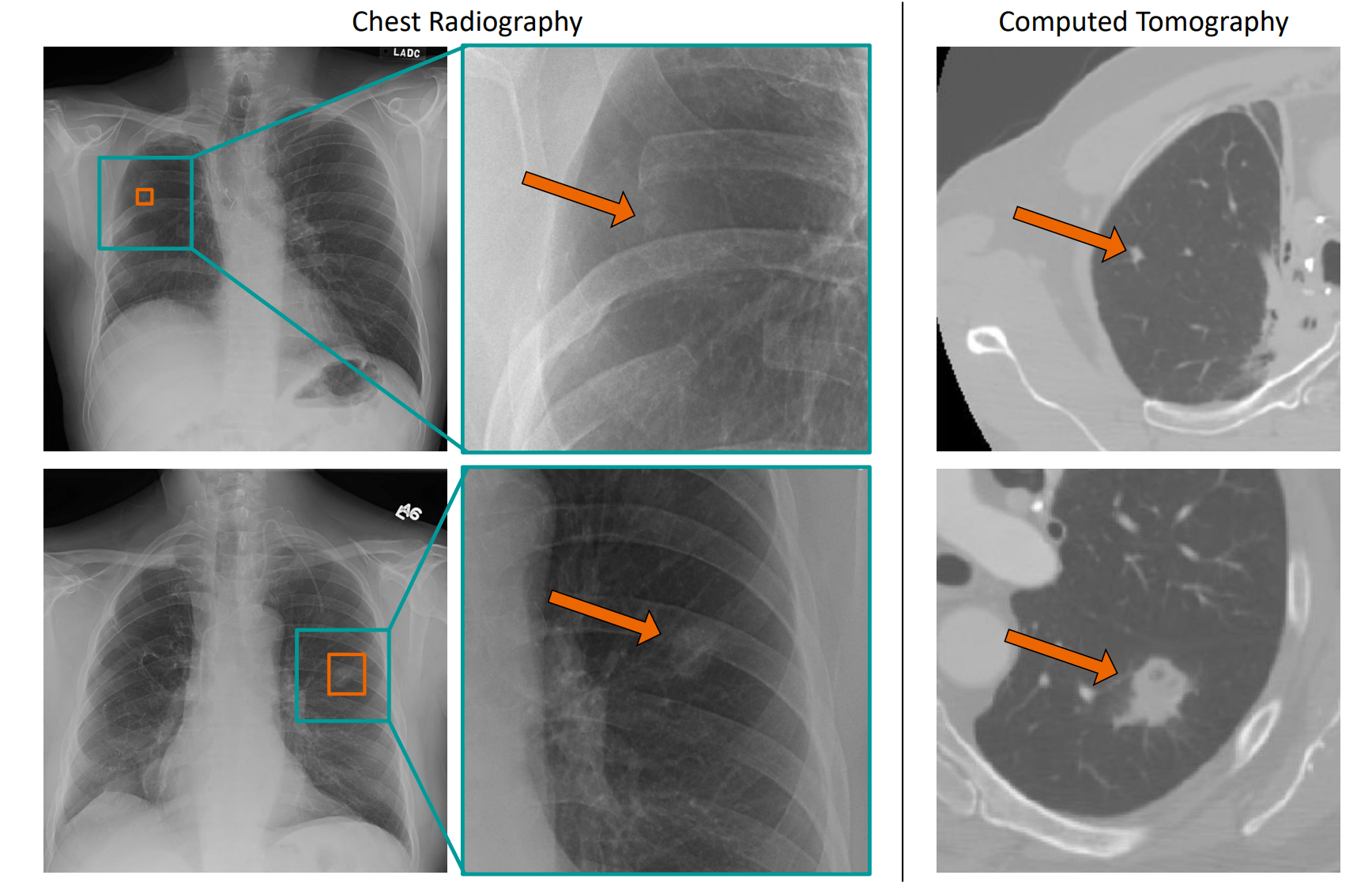
The researchers then trained the already pre-trained models with data sets labeled by Experts. The first model learned to recognize lung lesions and pneumothorax using about 300 labeled chest X-rays. A version of this first model learned to identify metastases to the brain in 3D MRI scans using 341 additional scans. A variant of the second model learned to detect brain hemorrhages in 3D CT scans using 3000 additional scans.

In all cases, these systems, based on the pre-trained models, demonstrated higher accuracy than current alternatives trained using only labeled data: Accuracy increased by six to eight percent. This is a remarkable achievement, especially without additional labeled data.
The systems were also more robust and learned their task up to 85 percent faster, the researchers write. Improvements in the future should enable faster AI training and thus faster iterations of the pre-trained models as well as more diverse models for further diagnostic tasks.





