Alibaba's Qwen AI unit releases capable new models to help developers write and analyze code

Alibaba's AI research unit Qwen has released a new series of AI models designed specifically for software development.
Called Qwen-2.5-Coder, these models help developers write, analyze, and understand code. The new series includes six different model sizes, ranging from 0.5 to 32 billion parameters, to accommodate various use cases and computing requirements.
Qwen tested these models in two practical applications: the AI-powered code editor Cursor and a web-based chatbot with artifact support similar to ChatGPT or Claude. Alibaba plans to integrate the chatbot functionality into its Tongyi cloud platform soon.
Video: Qwen
Video: Qwen
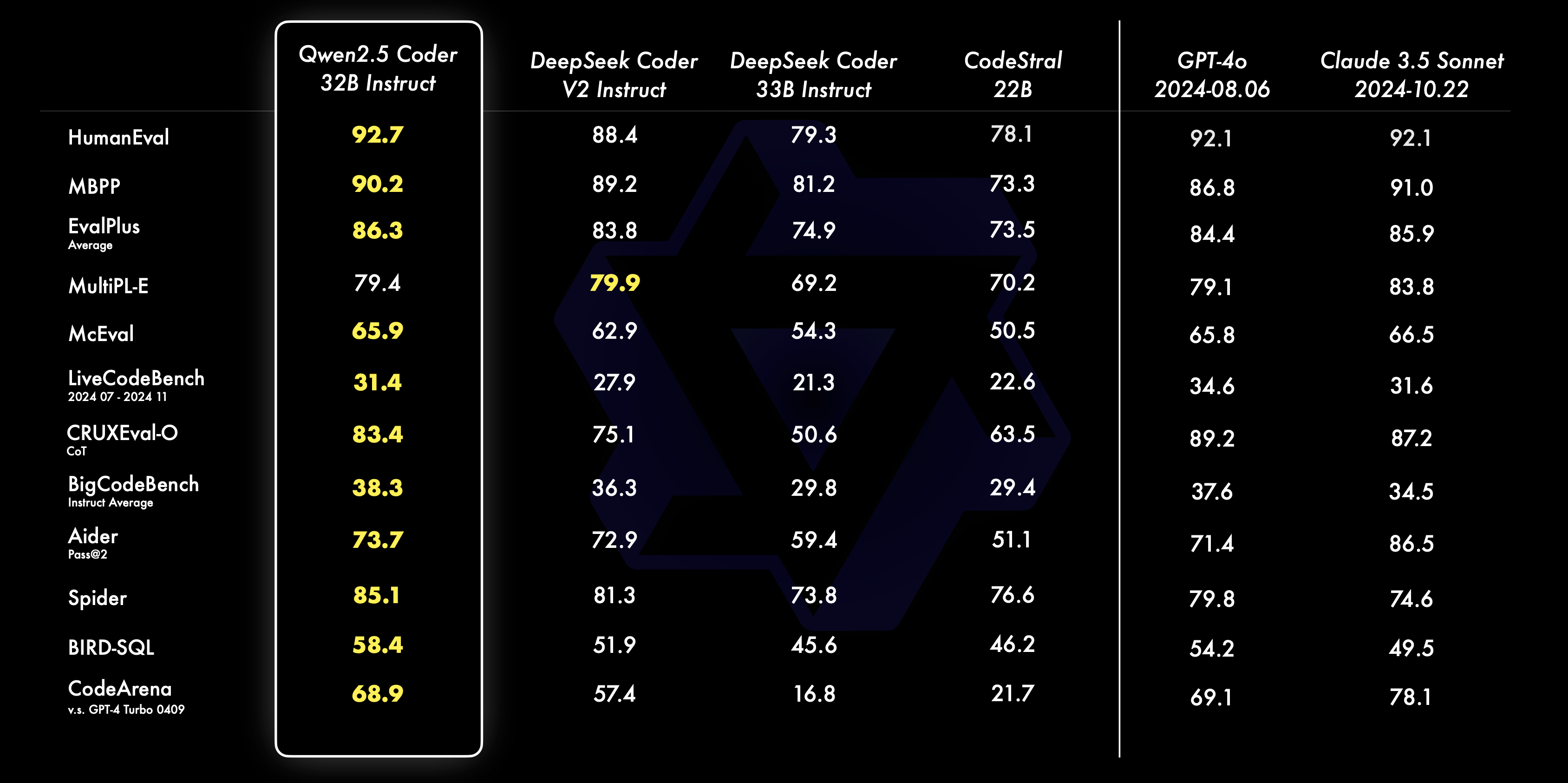
According to Qwen, their largest model, Qwen-2.5-Coder-32B-Instruct, outperformed other open-source systems like DeepSeek-Coder and Codestral in code generation benchmarks. The model also showed strong performance in general tasks like logical reasoning and language comprehension, though GPT-4o still leads in some benchmark tests.
Massive training datasets set token record
The models were trained on more than 20 trillion tokens of data from two sources: 18.5 trillion tokens from Qwen 2.5's general data mix introduced last September, plus 5.5 trillion tokens from public source code and programming-related web content. This makes it the first open-source model to exceed 20 trillion training tokens.
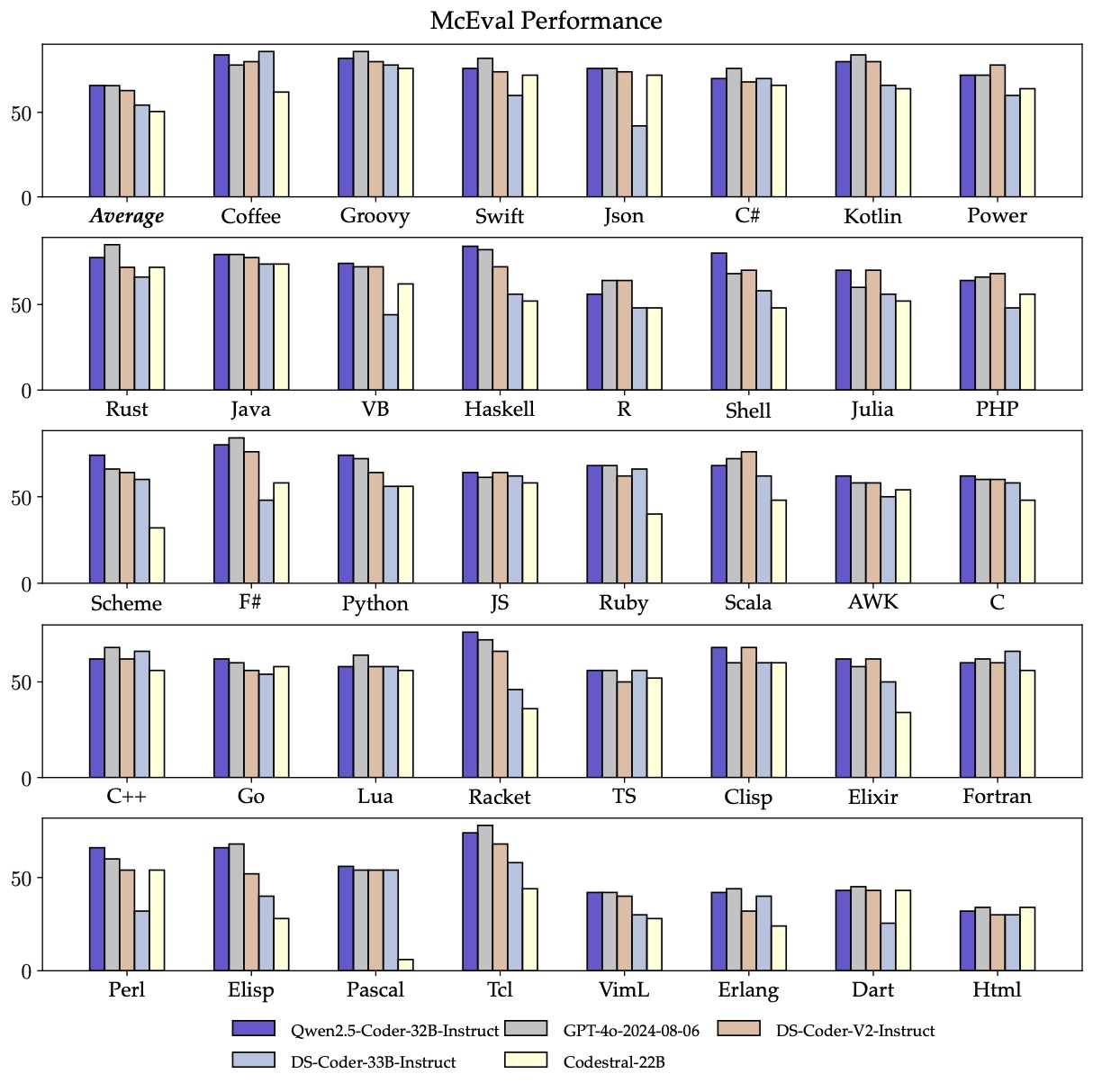
The top model, Qwen-2.5-Coder-32B-Instruct, supports over 40 programming languages, from common ones like Python, Java, and JavaScript to specialized languages like Haskell and Racket. All models feature context windows of up to 128,000 tokens.
Alibaba has released all models except the three-billion-parameter version under an Apache 2.0 license on GitHub. Developers can test the models through a free demo on Hugging Face.
Qwen researchers found that scaling up both model size and data consistently produced better results across programming tasks. The company says it plans to continue scaling to larger models and improving reasoning capabilities in future releases.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.