Similar to OpenAI with GPT-4 Turbo, Anthropic advertises its new chatbot Claude 2.1 as being able to process large amounts of text at once. However, as with Turbo, this works rather poorly.
The large context windows of OpenAI's GPT-4 Turbo and Anthropic's newly introduced Claude 2.1 model can process and analyze a large number of tokens (sentences and words) simultaneously. GPT-4 Turbo can handle up to 128,000 tokens (about 100,000 words), Claude 2.1 up to 200,000 tokens (about 150,000 words).
However, both models suffer from the "lost in the middle" phenomenon: information in the middle and near the top and bottom of a document is often ignored by the model.
Extracting information only works reliably at the beginning or end of a document
Greg Kamradt performed the same tests with Claude 2.1's context window as he did with GPT-4 Turbo by loading Paul Graham's essays into the system and placing statements at various locations in the document. He then tried to extract these statements and evaluated the performance of Claude 2.1 with GPT-4.
The results show that Claude 2.1 was able to extract facts at the beginning and end of a document with almost 100% accuracy for 35 queries.
However, the performance of the model drops off sharply above about 90,000 tokens, especially for information in the middle and bottom of the document. Looking at these results, it seems that information retrieval is so unreliable for larger context windows that it is basically useless in all cases where reliability is important. The performance degradation starts very early, at about 24K out of 200K tokens.

Large context windows are far from reliable
The result of the test is similar to that of OpenAI's GPT-4 Turbo, which Kamradt and others had previously tested. However, GPT-4 Turbo performed better than Claude 2.1 in the same test procedure, but also has a smaller context window.
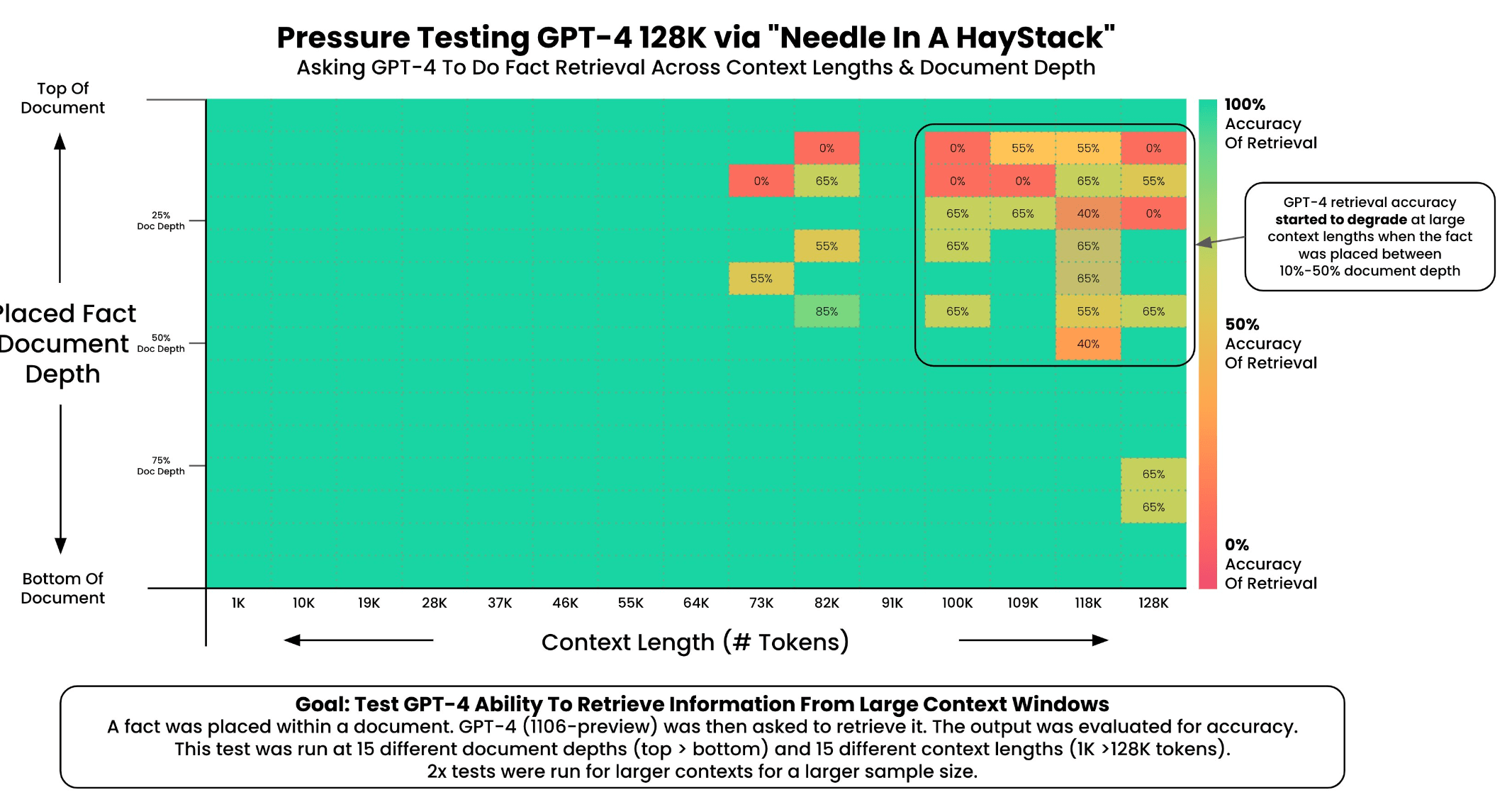
The conclusion is ultimately the same: facts in large documents are not guaranteed to be found in large context windows, and the location of information within a document plays a large role in accurate retrieval.
Large context windows are therefore no substitute for cheaper and more accurate vector databases, and reducing the size of the information you put in the context window increases accuracy.
If accurate retrieval is important for your use case, it is best to process information with language models in smaller units of 8k to 16k, even if you can put in 200k, or just use vector databases or search embeddings if you are building an AI application.