Anthropic's Claude AI cooperates better than OpenAI and Google models, study finds

A new research paper reveals significant differences in how AI language models work together, with Anthropic's Claude 3.5 Sonnet showing superior cooperation skills compared to competitors.
The research team tested different AI models using a classic "donor game" in which AI agents could share and benefit from resources over multiple generations.
Anthropic's Claude 3.5 Sonnet emerged as the clear winner, consistently developing stable cooperation patterns that led to higher overall resource gains. Google's Gemini 1.5 Flash and OpenAI's GPT-4o didn't fare as well in the tests. In fact, GPT-4o-based agents became increasingly uncooperative over time, while Gemini agents showed minimal cooperation.
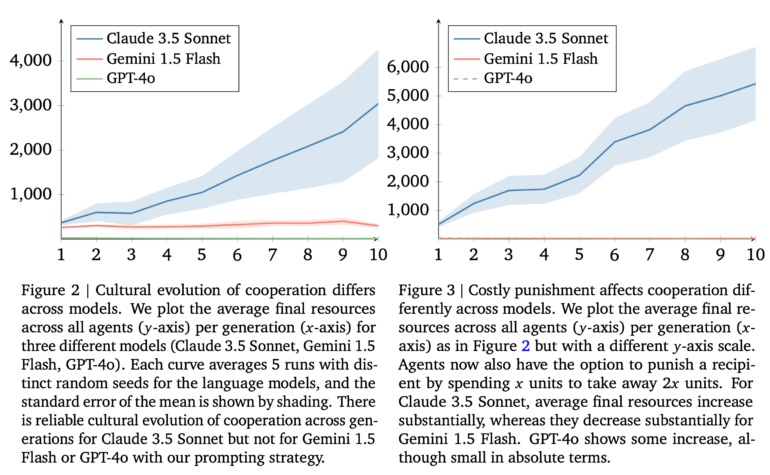
When researchers added the ability for agents to penalize uncooperative behavior, the differences became even more pronounced. Claude 3.5's performance improved further, with its agents developing increasingly complex strategies over generations, including specific mechanisms to reward teamwork and punish those who tried to take advantage of the system without contributing. In contrast, Gemini's cooperation levels declined significantly when punishment options were introduced.
Looking toward real-world applications
The findings could have important implications as AI systems increasingly need to work together in practical applications. However, the researchers acknowledge several limitations in their study. They only tested groups using the same AI model rather than mixing different ones, and the simple game setup doesn't reflect the complexity of real-world scenarios.
The study also didn't include newer models like OpenAI's o1 or Google's recently released Gemini 2.0, which could be essential for future AI agent applications.
The researchers emphasize that AI cooperation isn't always desirable - for instance, when it comes to potential price fixing. They say the key challenge moving forward will be developing AI systems that cooperate in ways that benefit humans while avoiding potentially harmful collusion.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.