Apple's new AI benchmarks show its models still lag behind leaders like OpenAI and Google

Apple has released new performance data for its two in-house AI models and opened up the smaller system to third-party developers. The benchmarks show that Apple's LLM technology still trails the competition.
Apple developed two models: a compact 3-billion-parameter version for on-device use, and a larger server-based model. In Apple's own benchmarks, the 3B model edges out similarly sized models like Qwen-2.5-3B and gets close to Qwen-3-4B and Gemma-3-4B. Apple credits efficiency improvements for narrowing the gap, but the small difference in size makes these claims less convincing.
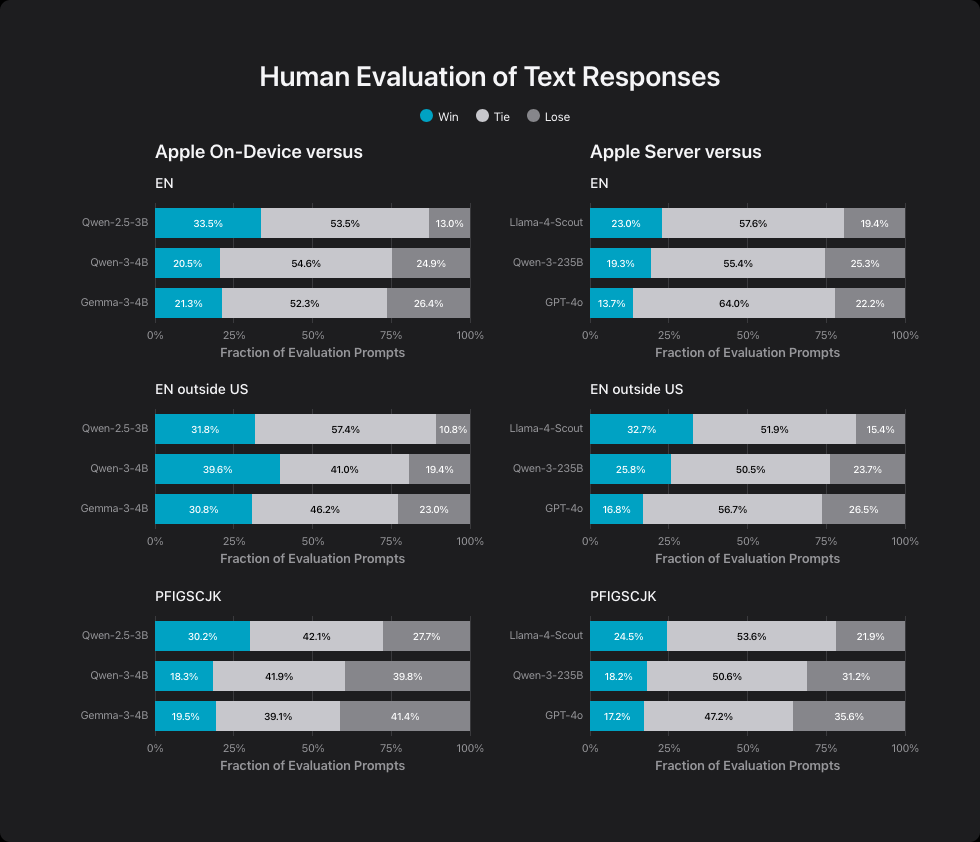
The server-based model performs on par with Llama-4-Scout. While Apple hasn't disclosed the parameter count, it says the model is similar in size to Meta's Scout, which has 109 billion total parameters and 17 billion active ones.
This server model uses a "parallel track mixture-of-experts" (MoE) architecture, allowing several smaller AI systems to run in parallel. Even so, it can't compete with much larger models like Qwen-3-235B or GPT-4o.
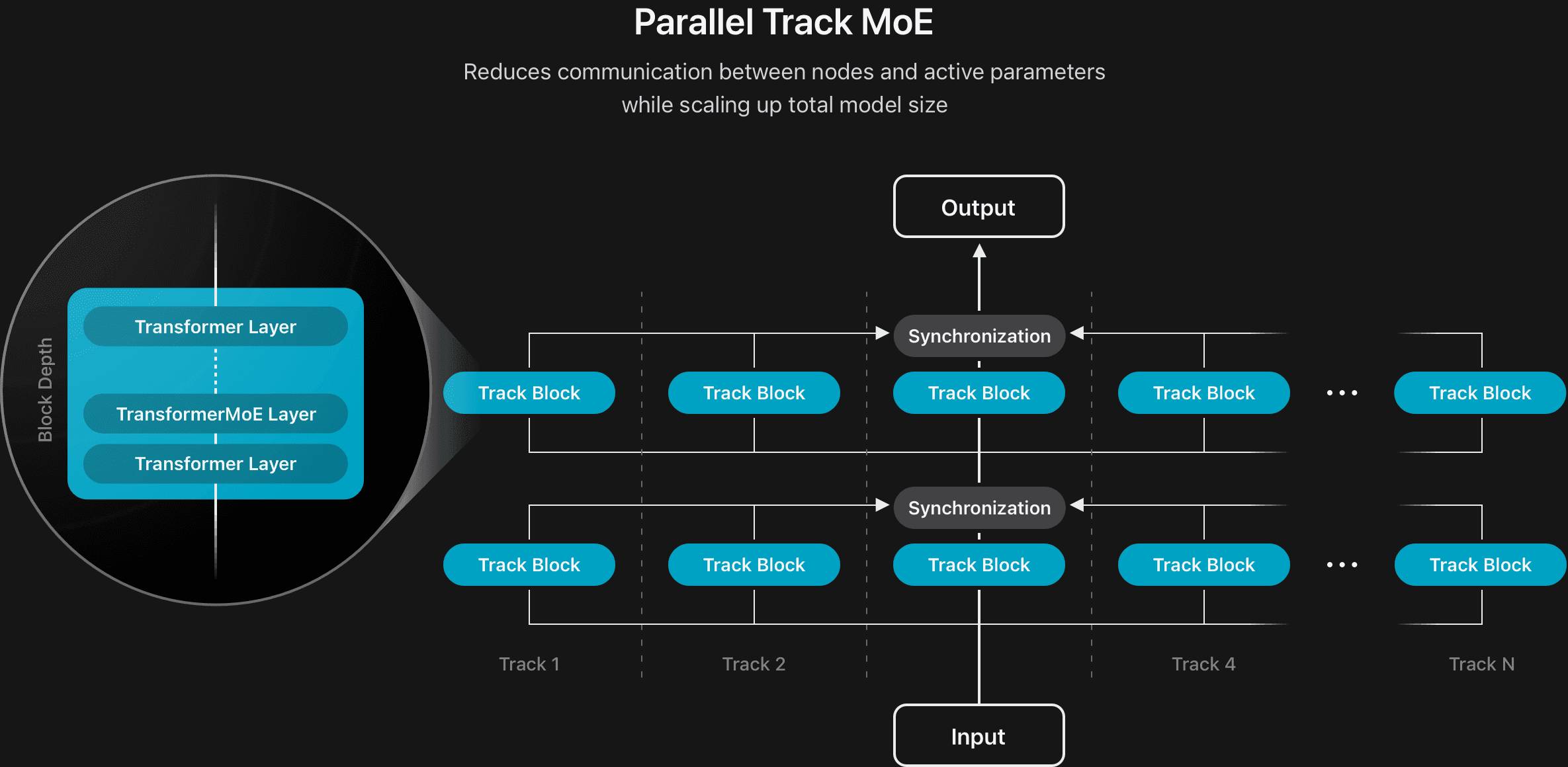
Apple uses aggressive compression to run the device model efficiently on iPhones and iPads, while the server model employs a specialized graphics compression technique.
Image recognition: Efficient, but not the leader
For image recognition, Apple's device model competes with InternVL-2.5-4B, Qwen-2.5-VL-3B-Instruct, and Gemma-3-4B. According to Apple, it outperforms InternVL and Qwen, but only matches Gemma-3-4B. The server model beats Qwen-2.5-VL-32B in less than half of test cases and still trails both Llama-4-Scout and GPT-4o.
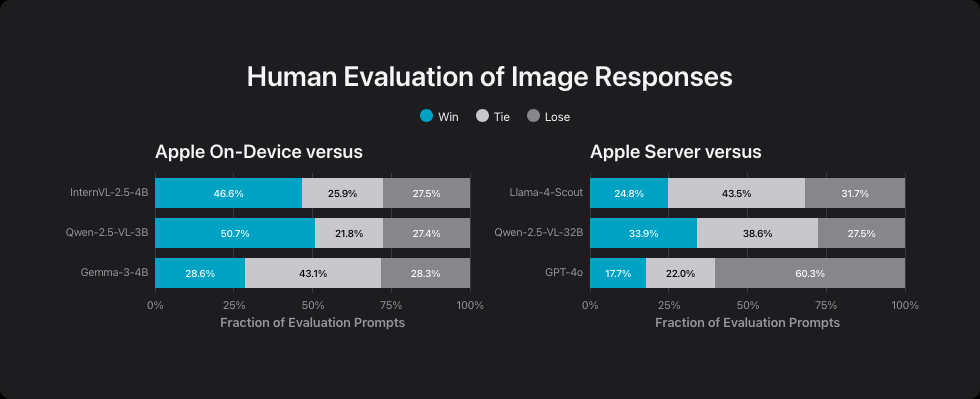
Apple uses different image recognition systems for each model: the server model runs on a 1-billion-parameter AI, while the device model uses a 300-million-parameter version. Both were trained on over ten billion image-text pairs and 175 million documents with embedded images.
Developers get the smaller model
Developers now have access to the 3-billion-parameter model via Apple's new Foundation Models Framework. Apple says this model works best for tasks like summarization, information extraction, and text understanding—not as an open-ended chatbot. The more powerful server model is reserved for Apple and powers Apple Intelligence features.
The framework offers free AI features and is integrated with Apple's Swift programming language. Developers can tag data structures for automatic, relevant outputs, and a tool API lets them extend the model's abilities.
To improve multilingual performance, Apple expanded the models' vocabulary from 100,000 to 150,000 words. The company ran culture-specific tests in 15 languages to ensure appropriate responses across different regions. Training data comes from "hundreds of billions of pages" collected by Applebot, Apple's web crawler.
According to the company, Applebot respects robots.txt exclusions and does not use any user data for training. Whether treating a lack of opt-out as consent for AI training remains up for debate.
Apple's latest benchmarks confirm what was already suspected ahead of this year's WWDC: the company's AI models are still catching up to competitors like Google and OpenAI. The results make clear that Apple's systems can't match the technical performance of market leaders.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.