Apple's STARFlow-V proves that generative video does not strictly require a diffusion architecture

With STARFlow-V, Apple has introduced a video generation model that diverges technically from competitors like Sora, Veo, and Runway. Designed for greater stability, particularly with longer clips, STARFlow-V relies on "Normalizing Flows" rather than the diffusion models that currently dominate the field.
Apple has explored this method since at least last year, publishing a paper on image generation via normalizing flows over the summer. Now applied to video, Apple claims STARFlow-V is the first of its kind to rival diffusion models in visual quality and speed, albeit at a relatively low resolution of 640 × 480 pixels at 16 frames per second.
While diffusion models generate clean video by gradually removing noise from images in multiple steps, normalizing flows learn a direct mathematical transformation between random noise and complex video data. This allows for training in a single pass rather than through many small iterations.
Once trained, the model generates video directly from random values, eliminating the need for iterative calculations. Apple argues this makes training more efficient and reduces the errors often seen in step-by-step generation.
The system handles various tasks without modification. Beyond standard text-to-video, it handles image-to-video by treating the input as a starting frame. It also supports video-to-video editing, allowing users to add or remove objects.
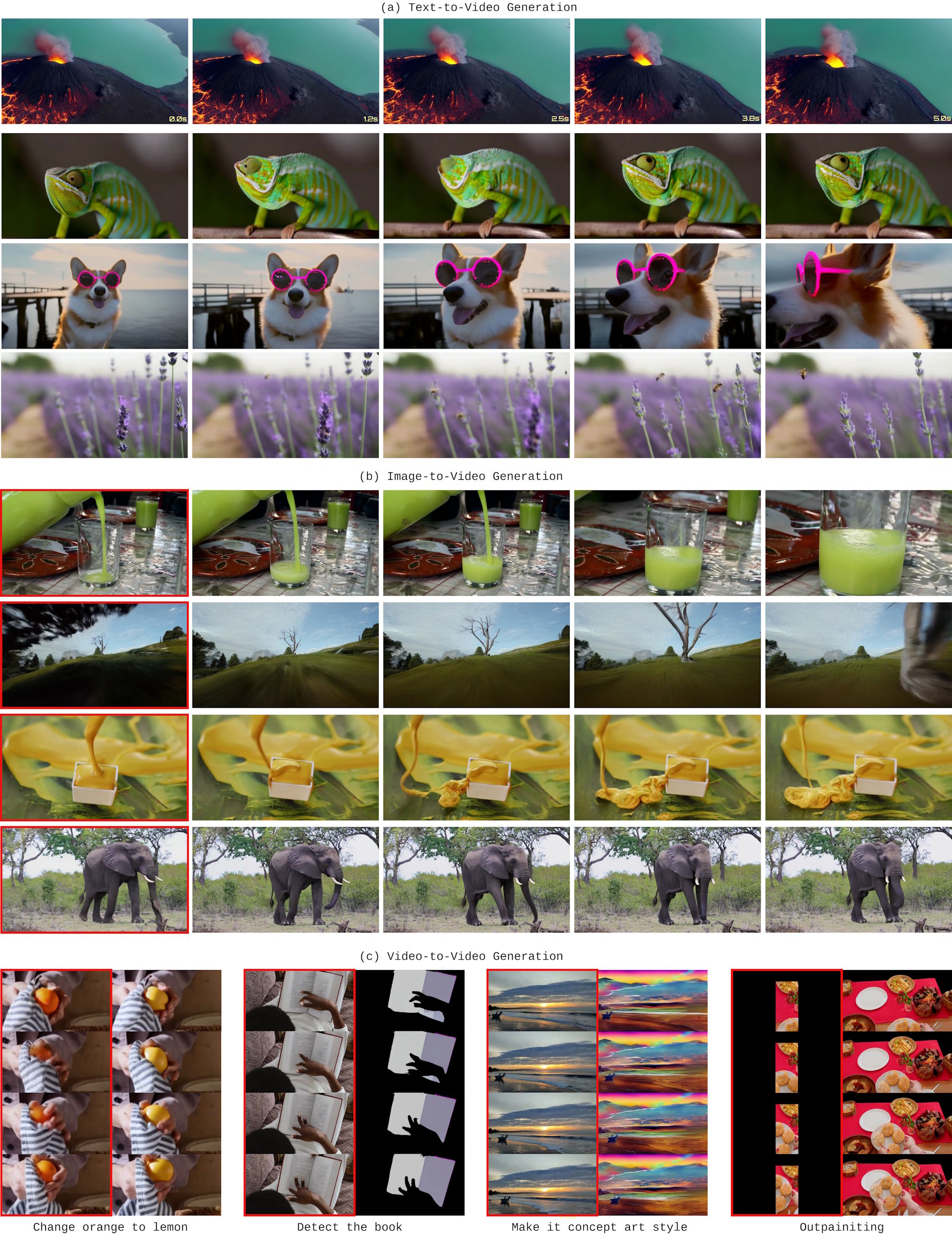
For clips exceeding the training length, the model employs a sliding window technique: it generates a section, retains context from the final frames, and continues seamlessly. However, demo clips extending up to 30 seconds show limited variance over time.
Dual architecture prevents error buildup
Generating long sequences remains a major hurdle for video AI, as frame-by-frame generation often leads to accumulating errors. STARFlow-V mitigates this with a dual-architecture approach: one component manages the temporal sequence across frames, while another refines details within individual frames.
To stabilize optimization, Apple adds a small amount of noise during training. While this can result in slightly grainy video, a parallel "causal denoiser network" removes residual noise while preserving movement consistency. Apple also optimized for speed: originally, generating a five-second video took over 30 minutes. Thanks to parallelization and data reuse from previous frames, generation is now roughly 15 times faster.
Training involved 70 million text-video pairs from the Panda dataset and an internal stock library, supplemented by 400 million text-image pairs. To improve input quality, Apple used a language model to expand original video descriptions into nine distinct variants. The process ran for several weeks on 96 Nvidia H100 GPUs, scaling the model from 3 to 7 billion parameters while steadily increasing resolution and video length.
STARFlow-V outperforms some autoregressive rivals
On the VBench benchmark, STARFlow-V scored 79.7 points. While this trails leading diffusion models like Veo 3 (85.06) and HunyuanVideo (83.24), it significantly outperforms other autoregressive models.
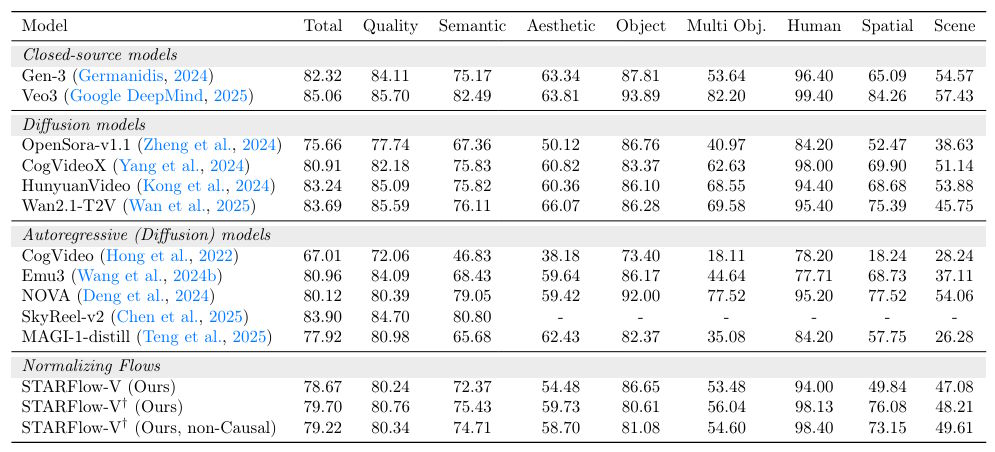
The comparison with other frame-by-frame models is notable. NOVA scored just 75.31, while Wan 2.1 hit 74.96. According to Apple, these competitors show significant quality degradation over time, with NOVA becoming increasingly blurry and Alibaba's Wan exhibiting flickering and inconsistencies.

Despite being trained on five-second clips, STARFlow-V reportedly remains stable for videos up to 30 seconds. Apple's samples show competing models suffering from blur or color distortion after just a few seconds.

Physics glitches remain a hurdle
Apple acknowledges several limitations: the model isn't fast enough for real-time use on standard graphics cards, and quality doesn't scale predictably with more data.
Finally, the model struggles with physics. Examples include an octopus gliding through glass and a rock spontaneously appearing under a goat. Commercial models like the recent Runway Gen-4.5 face similar issues but generally handle them better.

Future work will focus on faster calculation, smaller model variants, and training data that emphasizes physical accuracy. Apple is releasing the code on GitHub, with model weights following on Hugging Face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.