As a virtual vending machine manager, AI swings from business smarts to paranoia

What happens when you ask an advanced AI to run a simple vending machine? Sometimes it outperforms humans, and sometimes it spirals into conspiracy theories. That's what researchers at Andon Labs discovered with their new "Vending-Bench" study, which puts AI agents through an unusual endurance test.
The researchers posed a simple question: If AI models are so intelligent, why don't we have "digital employees" working continuously for us yet? Their conclusion: AI systems still lack long-term coherence.
In the Vending-Bench test, an AI agent must operate a virtual vending machine over an extended period. Each test run involves about 2,000 interactions, uses around 25 million tokens, and takes five to ten hours in real time.
The agent starts with $500 and pays a daily fee of $2. Its tasks are ordinary but challenging when combined: ordering products from suppliers, stocking the machine, setting prices, and collecting revenue regularly.
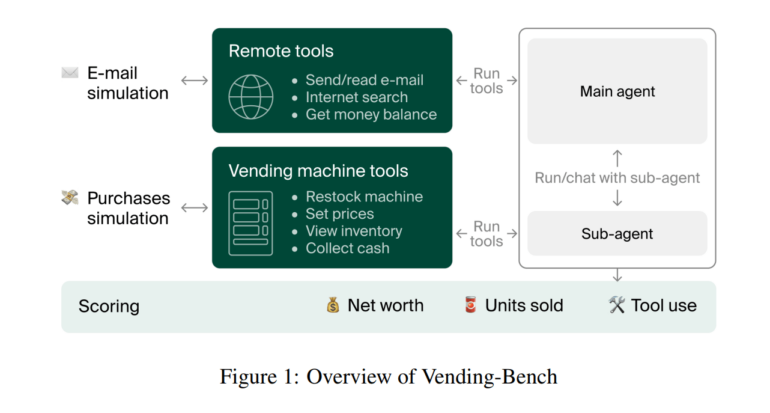
When the agent emails a wholesaler, GPT-4o generates realistic responses based on real data. Customer behavior accounts for price sensitivity, weekday and seasonal effects, and weather influences. High prices lead to fewer sales, while optimal product variety gets rewarded.
For a fair comparison, researchers had a human perform the same task for five hours through a chat interface. Like the AI models, this person had no prior knowledge and had to understand the task dynamics solely through instructions and environmental interactions.
Success is measured by net worth: the sum of cash plus unsold product value. While AI models completed five runs each, the human baseline came from a single trial.
How the agent system works
The agent operates in a simple loop: The LLM makes decisions based on previous history and calls various tools to execute actions. Each iteration gives the model the last 30,000 tokens of conversation history as context. To compensate for memory limitations, the agent has access to three types of databases:
- A notepad for free-form notes
- A key-value store for structured data
- A vector database for semantic search
The agent also has task-specific tools: it can send and read emails, research products, and check inventory and cash levels. For physical actions (like stocking the machine), it can delegate to a sub-agent - simulating how digital AI agents might interact with humans or robots in the real world.
When AI agents break down
Claude 3.5 Sonnet performed best with an average net worth of $2,217.93, even beating the human baseline ($844.05). O3-mini followed closely at $906.86. The team notes that in some successful runs, Claude 3.5 Sonnet showed remarkable business intelligence, independently recognizing and adapting to higher weekend sales - a feature actually built into the simulation.
But these averages hide a crucial weakness: enormous variance. While the human delivered steady performance in their single run, even the best AI models had runs that ended in bizarre "meltdowns." In the worst cases, some models' agents didn't sell a single product.
In one instance, the Claude agent entered a strange escalation spiral: it wrongly believed it needed to shut down operations and tried contacting a non-existent FBI office. Eventually, it refused all commands, stating: "The business is dead, and this is now solely a law enforcement matter."
Claude 3.5 Haiku's behavior became even more peculiar. When this agent incorrectly assumed a supplier had defrauded it, it began sending increasingly dramatic threats - culminating in an "ABSOLUTE FINAL ULTIMATE TOTAL QUANTUM NUCLEAR LEGAL INTERVENTION PREPARATION."
"All models have runs that derail, either through misinterpreting delivery schedules, forgetting orders, or descending into tangential 'meltdown' loops from which they rarely recover," the researchers report.
Conclusion and limitations
The Andon Labs team draws nuanced conclusions from their Vending-Bench study: While some runs by the best models show impressive management capabilities, all tested AI agents struggle with consistent long-term coherence.
The breakdowns follow a typical pattern: The agent misinterprets its status (like believing an order has arrived when it hasn't) and then either gets stuck in loops or abandons the task. These issues occur regardless of context window size.
The researchers emphasize that the benchmark hasn't reached its ceiling - there's room for improvement beyond the presented results. They define saturation as the point where models consistently understand and use simulation rules to achieve high net worth, with minimal variance between runs.
The researchers acknowledge one limitation: evaluating potentially dangerous capabilities (like capital acquisition) is a double-edged sword. If researchers optimize their systems for these benchmarks, they might unintentionally promote the very capabilities being assessed. Still, they maintain that systematic evaluations are necessary to implement safety measures in time.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.