AI is reshaping the media landscape. Some companies are striking partnerships, others are fighting back against alleged copyright infringement, and some are doing both. To keep track of this shifting terrain, Columbia University's Tow Center has launched an "AI Deals and Disputes Tracker." The tool, part of the center's "Platforms and Publishers" project, monitors the evolving relationship between news publishers and AI companies by documenting lawsuits, business deals, and financial grants based on publicly available information.
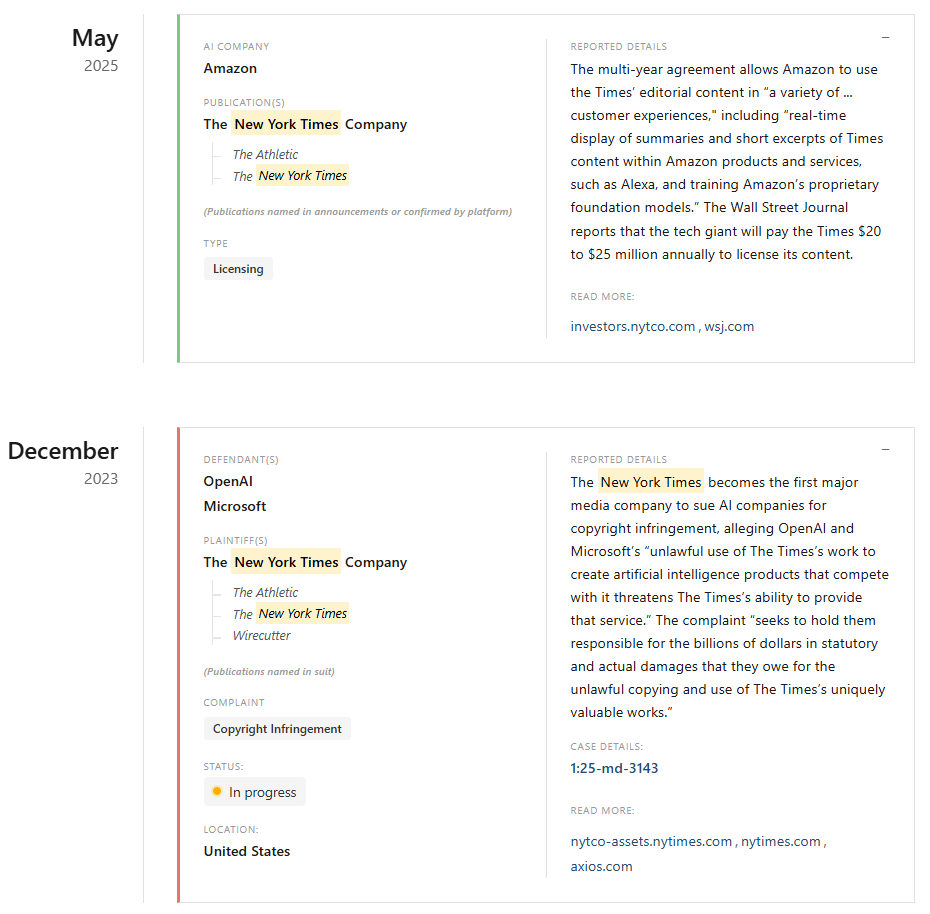
The Tow Center says the overview gets updated at the start of each month, with the most recent data from December 12, 2025. The goal is to give readers a clear picture of the legal and economic shifts happening across the industry. Klaudia Jaźwińska compiles the data and welcomes tips on missing developments to keep the tracker up to date.



