OpenAI's ChatGPT benefits from training with human feedback. Google is now looking at how this method can also improve computer vision models.
The first deep-learning models for object recognition were based on supervised learning with a massive number of labeled images. For example, an image of a cat comes with the digital label "cat". In this way, the system learns the relationship between the word and the image.
With the advent and success of the Transformer architecture in language processing, researchers began to successfully apply Transformers and self-supervised learning to computer vision.
Only training with labeled images became obsolete: Like text models, image models learned from large amounts of unstructured data. Google's Vision Transformer was one of the first architectures to reach the level of older, supervised models.
Reinforcement learning can improve pre-trained AI models
Following the release of the large language model GPT-2, OpenAI began to experiment with training language models using reinforcement learning with human feedback (RLHF). This is because large, pre-trained language models, while extremely versatile, are difficult to control - a fact that Microsoft is currently experiencing with its Bing chatbot.
RLHF, on the other hand, uses reward signals to teach a large language model which text generations are desirable and which are incorrect or undesirable. As ChatGPT shows, this results in a more aligned model and appears to have a positive effect on the overall performance of the system.
Google researchers have now taken this finding and tested whether computer vision models can also benefit from reinforcement learning (RL) with reward signals. The team trained several vision transformer models and then used a simple reinforcement learning algorithm to optimize them for specific tasks such as object recognition, panoptic segmentation or image coloring.
Computer vision models also benefit from reward signals
The team shows that the object recognition and panoptic segmentation models improved with RL are on par with models specialized for these tasks. The colorization model also performs better thanks to RL.
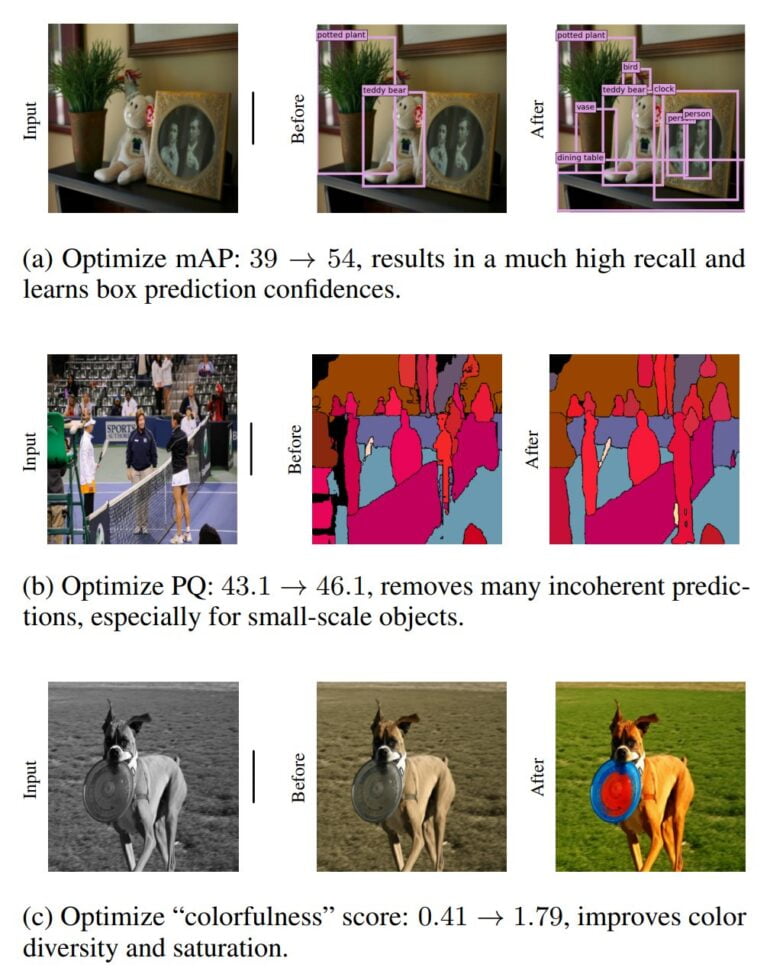
As a proof-of-concept study, Google's work shows that finetuning computer vision models via reinforcement learning works similarly to natural language processing, and can lead to better models.

The next step would be to combine these reward signals with human feedback - as is the case with ChatGPT. The researchers see this as a promising area of research and would like to apply RLHF in computer vision to challenging tasks such as tuning scene understanding outputs for robot grasping. Here, RLHF could enable better perception models and raise the probability of a successful grasp.

