Claude Jailbreak results are in, and the hackers won

Update –
- Jailbreak update 2
Update from February 15, 2025:
The results from Anthropic's Claude jailbreaking challenge are in. After five intense days of probing - involving over 300,000 messages and what Anthropic estimates was 3,700 hours of collective effort - the AI system's defenses finally cracked.
Jan Leike, an Anthropic researcher, shared on X that four participants successfully made it through all challenge levels. One participant managed to discover a universal jailbreak - essentially a master key to bypass Claude's safety guardrails. Anthropic is paying out a total of $55,000 to the winners.
The challenge demonstrated that safety classifiers, while helpful, aren't sufficient protection on their own, Leike says. This aligns with what we've been learning from other recent AI safety research - there's rarely a silver bullet solution, and the probabilistic nature of these models makes securing them particularly challenging.
Leike emphasizes that as models become more capable, robustness against jailbreaking becomes a key safety requirement to prevent misuse related to chemical, biological, radiological, and nuclear risks.
Update from February 11, 2025:
Within just six days of launching the challenge, someone managed to bypass all the security mechanisms designed to protect Anthropic's AI model.
Jan Leike, a former OpenAI alignment team member now working at Anthropic, announced on X that one participant successfully broke through all eight levels of the challenge. The collective effort involved around 3,700 hours of testing and 300,000 messages from participants. However, Leike notes that no one has yet discovered a universal jailbreak that could solve all challenge levels at once.
After ~300,000 messages and an estimated ~3,700 collective hours, someone broke through all 8 levels.
However, a universal jailbreak has yet to be found... https://t.co/xpj2hfGC6W
— Jan Leike (@janleike) February 9, 2025
As AI models become more capable, protecting them becomes increasingly critical - and universal jailbreaks grow more valuable. This dynamic suggests that language models might eventually develop their own security ecosystem, similar to what exists today for operating systems.
Original article from February 04, 2025
The AI company Anthropic has developed a method to protect language models from manipulation attempts.
Anthropic has developed a new safety method called "Constitutional Classifiers" to prevent people from tricking AI models into giving harmful responses. The technology specifically targets universal jailbreaks - inputs designed to systematically bypass all safety measures.
To put the system through its paces, Anthropic recruited 183 people to try breaking through its defenses over two months. The participants attempted to get the AI model Claude 3.5 to answer ten prohibited questions. Even with $15,000 in prize money and roughly 3,000 hours of testing, no one managed to bypass all the safety measures.
Early challenges lead to improvements
The initial version had two main drawbacks: it flagged too many innocent requests as dangerous and required too much computing power. While an improved version addressed these issues, as shown in automated tests with 10,000 jailbreak attempts, some challenges remain.
The tests revealed that while an unprotected Claude model allowed 86 percent of manipulation attempts through, the protected version blocked more than 95 percent. The system only incorrectly flagged an additional 0.38 percent of harmless requests, though it still needs 23.7 percent more computing power to run.
Synthetic training data as a basis
The safety system works by using predefined rules about what content is allowed or prohibited. Using this "constitution", it creates synthetic training examples in various languages and styles. These examples then train the classifiers to spot suspicious inputs.
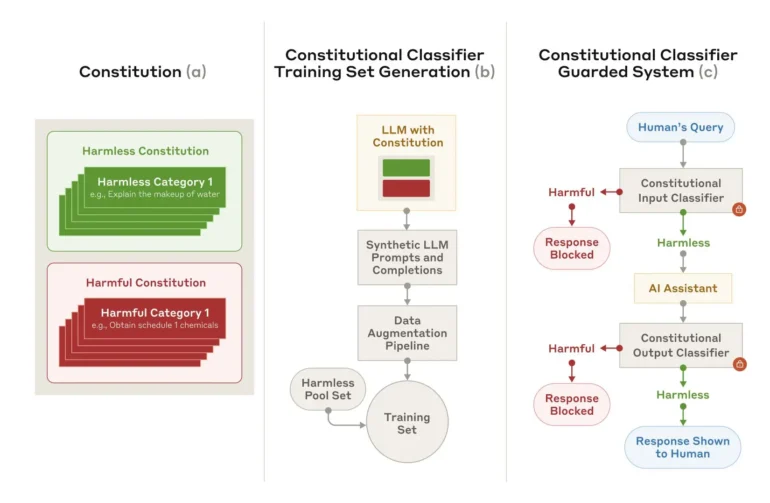
The researchers acknowledge that the system isn't foolproof against every universal jailbreak, and new attack methods could emerge that it can't handle. That's why Anthropic suggests using it alongside other safety measures.
To further test the system's strength, Anthropic has released a public demo version. safety experts can try to outsmart it from February 3 to 10, 2025, with results to be shared in an update.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.