Cohere's new vision model can process images, diagrams, PDFs, and other types of visual data
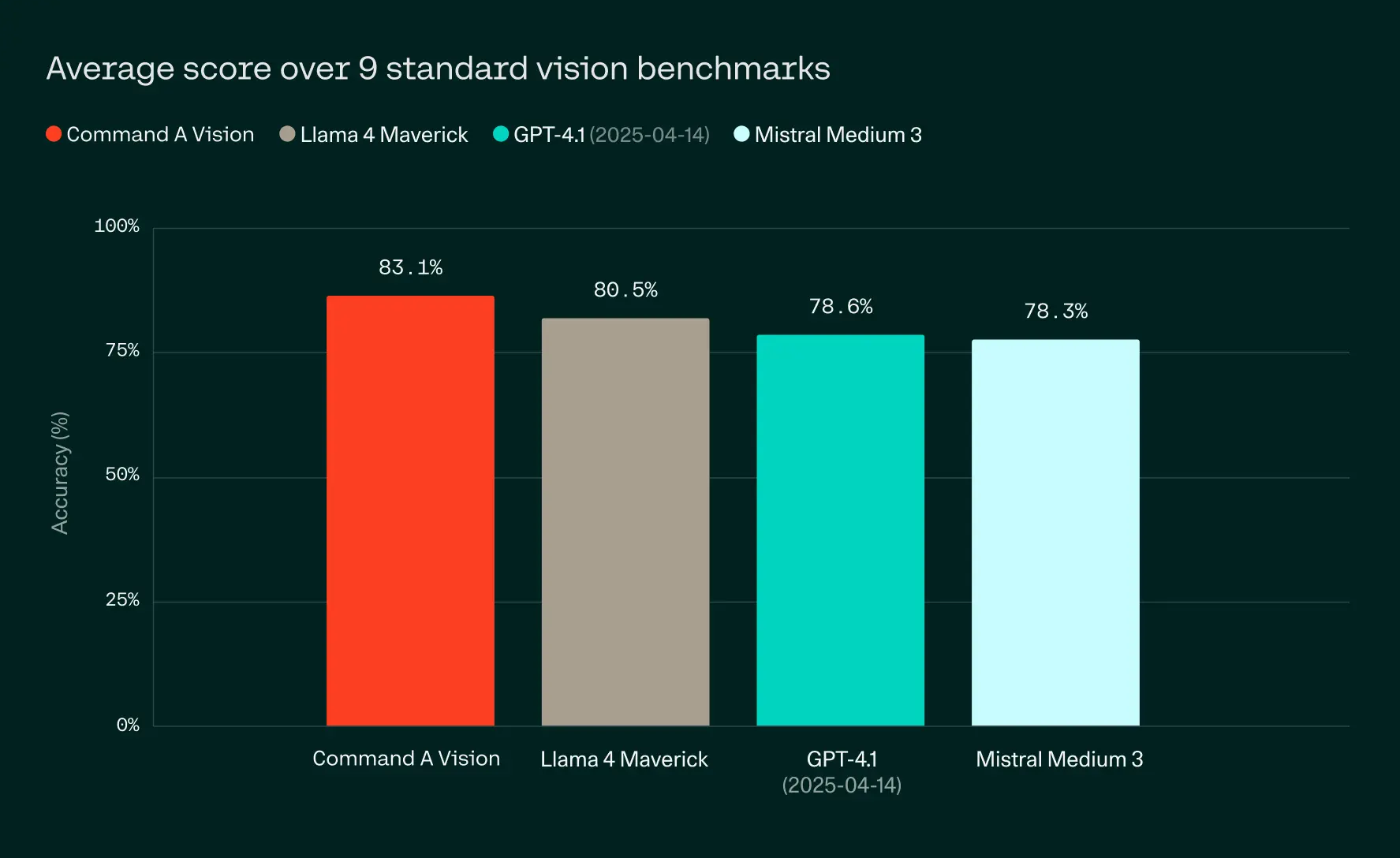
Cohere's new Command A Vision model is designed to handle images, diagrams, PDFs, and other types of visual data. Cohere says the model outperforms GPT-4.1, Llama 4 Maverick, Pixtral Large, and Mistral Medium 3 on standard vision benchmarks.
The model's OCR can recognize both the text and the structure of documents such as invoices and forms, outputting the extracted data in structured JSON. Command A Vision can also process real-world images, like identifying potential risks in industrial environments, the company says.
Command A Vision is available through the Cohere platform and for research on Hugging Face. The model can run locally with either two A100 GPUs or a single H100 using 4-bit quantization.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.