Corporate AI agents use simple workflows with human oversight instead of chasing full autonomy

While researchers chase fully autonomous AI agents, companies are taking a different path.
A new study called "Measuring Agents in Production" from researchers at UC Berkeley, Intesa Sanpaolo, UIUC, Stanford University, and IBM Research found that successful teams aren't building autonomous super agents. They're relying on simple workflows, manual prompting, and heavy human oversight.
The researchers surveyed 306 practitioners and conducted 20 in-depth interviews with teams running deployed agents, including systems in full production and final pilot phases.
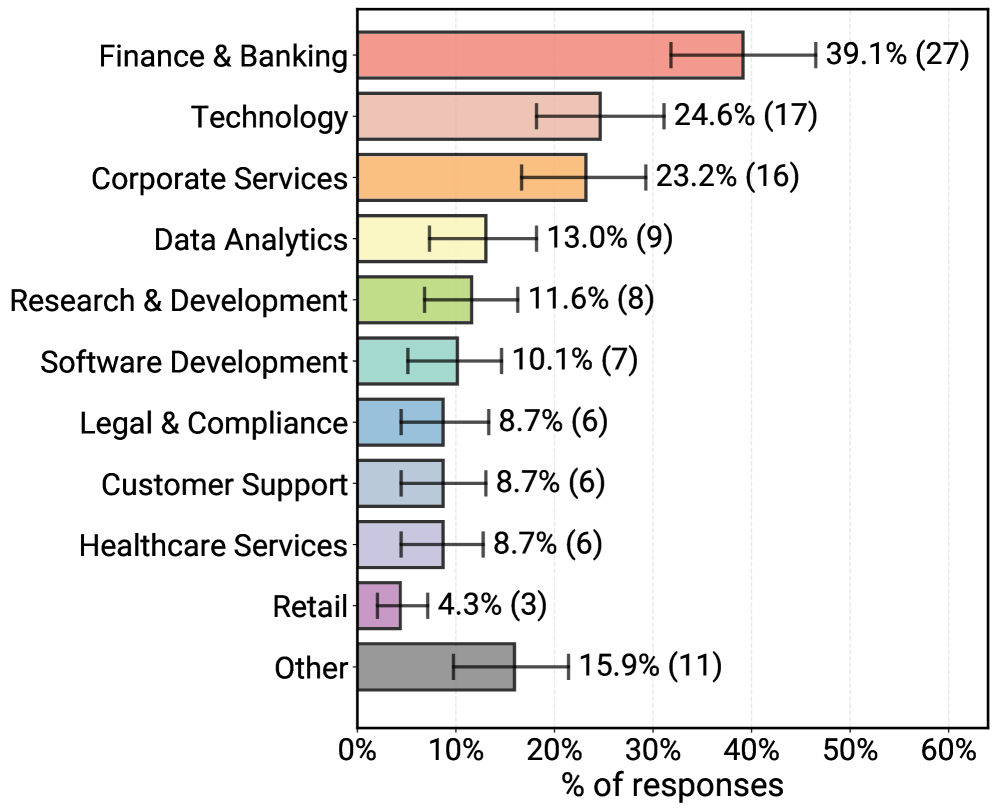
The study defines agents as "systems that combine foundation models with optional tools, memory, and reasoning capabilities to autonomously execute multi-step tasks."
Companies want control, not "AI employees"
Academic papers often showcase agents performing dozens of complex steps. Production systems are far more restrained. Instead of fully autonomous "AI employees," companies deploy limited systems built on frontier language models, extensive prompts, and strict human guardrails. About 68 percent of productive agents in the study perform fewer than ten steps before requiring human intervention, and nearly half (47 percent) handle fewer than five.
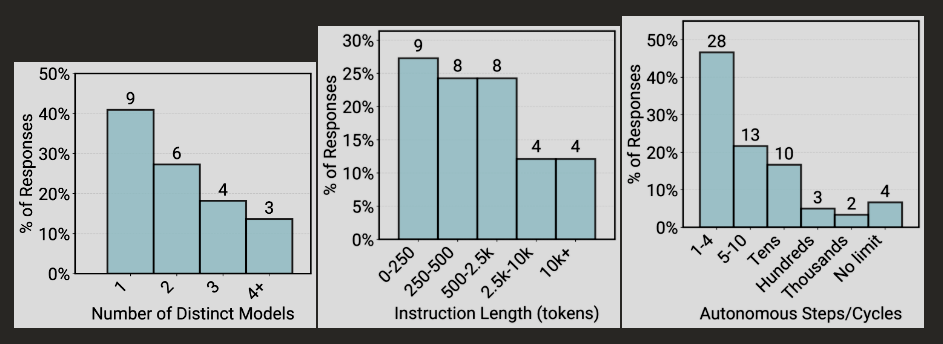
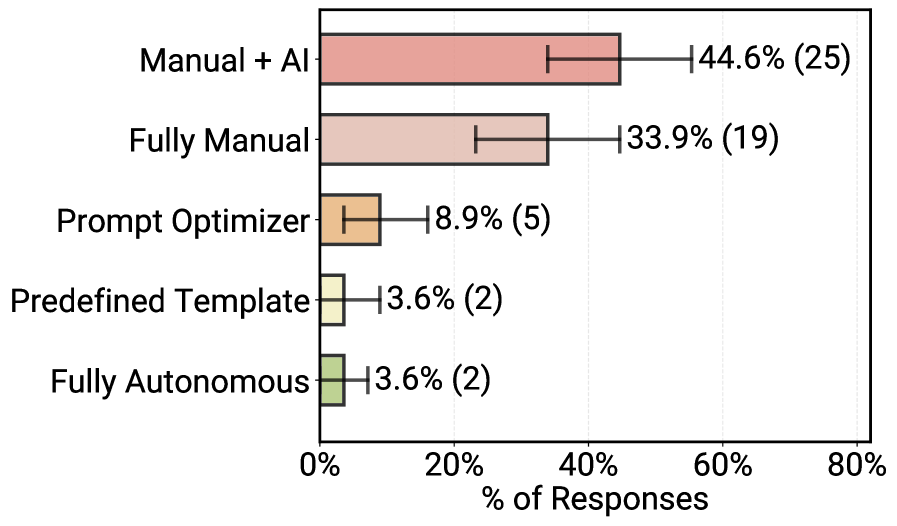
Practitioners explicitly prefer simple, controllable approaches. Roughly 70 percent of teams use off-the-shelf models without fine-tuning. Reinforcement learning is virtually absent. Instead, teams pour their effort into manual prompt engineering.
That said, there are early signs of increasing autonomy. Some teams use "router" agents that analyze requests and forward them to specialized sub-agents. Others split work between generator agents and verifier agents, with the latter systematically checking responses for accuracy.
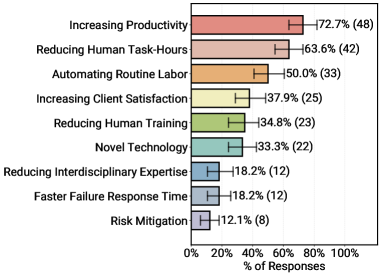
Time savings matter more than speed
Among teams with deployed systems, 72.7 percent picked "increasing productivity" as a key benefit - the most frequently cited reason. Reducing human work hours (63.6 percent) and automating routine tasks (50 percent) follow closely. Risk reduction ranks last at just 12.1 percent, largely because time savings are easier to measure than stability improvements.
Speed requirements are surprisingly loose. For 41.5 percent of agents, response times in the minute range work fine. Only 7.5 percent of teams demand sub-second responses, and 17 percent have no fixed latency budget at all.
Since these agents often handle tasks that previously took humans hours or days, waiting five minutes for a complex search feels fast enough. Asynchronous workflows like nightly reports reinforce this flexibility. Latency only becomes a concern for voice or chat agents with immediate user interaction.
Despite the hype around AI-to-AI ecosystems, 92.5 percent of productive systems serve humans directly. Only 7.5 percent interact with other software or agents. In just over half the cases, users are internal employees, while 40.3 percent are external customers. Most organizations keep agents internal initially to catch errors, treating them as tools for domain experts rather than replacements. Humans generally retain final decision-making power.
Production teams build from scratch
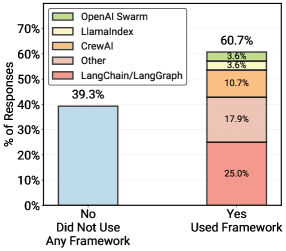
Among deployed systems in the survey, about 61 percent use frameworks like LangChain/LangGraph or CrewAI. But the in-depth interviews tell a different story. In 20 case studies of deployed agents, 85 percent of teams build their applications from scratch without third-party frameworks.
Developers cite control and flexibility as the main reasons. Frameworks often introduce "dependency bloat" and complicate debugging. Custom implementations using direct API calls are simply easier to maintain in production.
Workflows also stay static. About 80 percent of analyzed agents follow fixed paths with clearly defined subtasks. An insurance agent, for example, might always run through a set sequence: coverage check, medical necessity check, risk identification. The agent has some autonomy within each step, but the overall path is rigid.
Making AI reliable is the hardest problem
Getting non-deterministic models to work reliably is the hardest part of development. Respondents ranked "core technical performance"—specifically robustness, reliability, and scalability—as their biggest challenge, far ahead of compliance or governance. Teams don't ignore security and data protection, but they view these as manageable within their often highly contained scenarios.
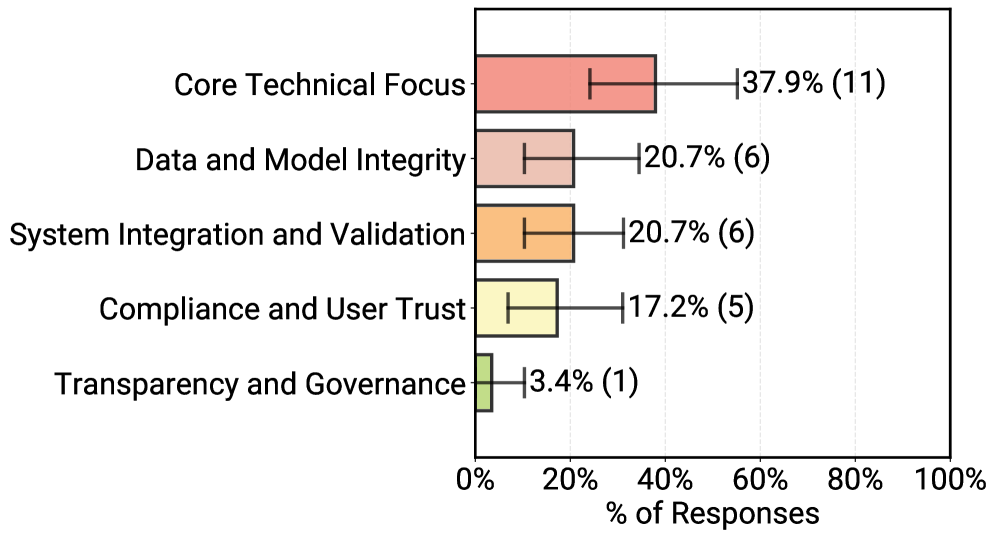
Evaluation methods reflect this uncertainty. Most teams (74 percent) rely on human-in-the-loop evaluation. While 52 percent use "LLM-as-a-Judge" systems, they almost always pair it with human review. A typical setup has an LLM score a response; if the score is low, a human steps in.
Because agents usually perform highly specific tasks, public benchmarks rarely apply. As a result, 75 percent of surveyed teams evaluate their systems without formal benchmarks, relying on A/B testing or direct user feedback instead.
For model selection, proprietary frontier models like OpenAI's GPT series or Anthropic's Claude dominate. Open-source models generally appear only when strict regulations or high-volume costs make them necessary. Teams are pragmatic: they pick the most efficient model that fits their budget and compliance rules.
Research risks losing touch with reality
The MAP study serves as a reality check. It highlights a disconnect between research papers—which often focus on complex multi-agent scenarios and automated prompting—and the simple, controllable architectures actually running in production. The authors warn that research ignoring these production realities risks becoming irrelevant.
Despite the limitations, the agent hype isn't entirely groundless. Teams cite productivity and efficiency as their primary reasons for deploying agents in fields like insurance and HR. These systems handle routine knowledge work, leaving complex decisions to human experts. The study provides no concrete figures on productivity gains, relying instead on perceived benefits reported by practitioners.
Agentic behavior is becoming invisible
Beyond the systems documented in the MAP study, large reasoning models are increasingly functioning as agents, though this falls outside the scope of the specific research. For instance, it is now standard for an AI system to independently decide when to search the internet or write code while handling a user request.
Much of this agentic behavior remains invisible to users. The only noticeable sign may be a longer wait time—minutes rather than seconds—as the system carries out "deep research" or intricate reasoning processes behind the scenes. In reality, agentic AI is already far more prevalent than most realize. Deepmind CEO Demis Hassabis expects this form of agency to become more reliable over the next year, addressing a central criticism of the field.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.