Gemini Diffusion could be Google's most important I/O news that slipped under the radar

Google is testing a new kind of language model called Gemini Diffusion—an experimental system that generates text using diffusion techniques instead of traditional word-by-word prediction.
Instead of generating text one word at a time like traditional language models, Gemini Diffusion borrows a technique from image generation: refining noise in multiple passes.
The system starts with random noise and gradually shapes it into full sections of text, allowing for midstream corrections and tighter control over the output. Deepmind says this approach leads to more consistent and logically connected output, making it especially effective for tasks like code generation and text editing, where precision, coherence, and iteration are key.
Video: Google
Fast and competitive
Gemini Diffusion generates full sections of text at once—and does so much faster than traditional autoregressive models that work left to right. Deepmind reports a speed of 1,479 tokens per second (excluding overhead), with initial latency as low as 0.84 seconds.
Brendan O'Donoghue, a researcher at Deepmind, says the model can reach up to 2,000 tokens per second on programming tasks, even when accounting for overhead like tokenization, prefill, and safety checks.
Video: Google Deepmind
Oriol Vinyals, VP of Research and Deep Learning Lead at Google Deepmind and Co-Head of the Gemini project, described the release of Gemini Diffusion as a personal milestone. "It's been a dream of mine to remove the need for 'left to right' text generation," he said. The model ran so fast during the demo that they had to slow the video down just to make it watchable.
In benchmarks, Gemini Diffusion performs about as well overall as Gemini 2.0 Flash Lite. On programming tasks like HumanEval (89.6% vs. 90.2%) and MBPP (76.0% vs. 75.8%)—two common coding benchmarks—the results are nearly identical.
In fact, Gemini Diffusion pulls slightly ahead in LiveCodeBench (30.9% vs. 28.5%) and LBPP (56.8% vs. 56.0%). But it falls short in other areas, scoring lower on the scientific reasoning benchmark GPQA Diamond (40.4% vs. 56.5%) and the multilingual Global MMLU Lite test (69.1% vs. 79.0%).
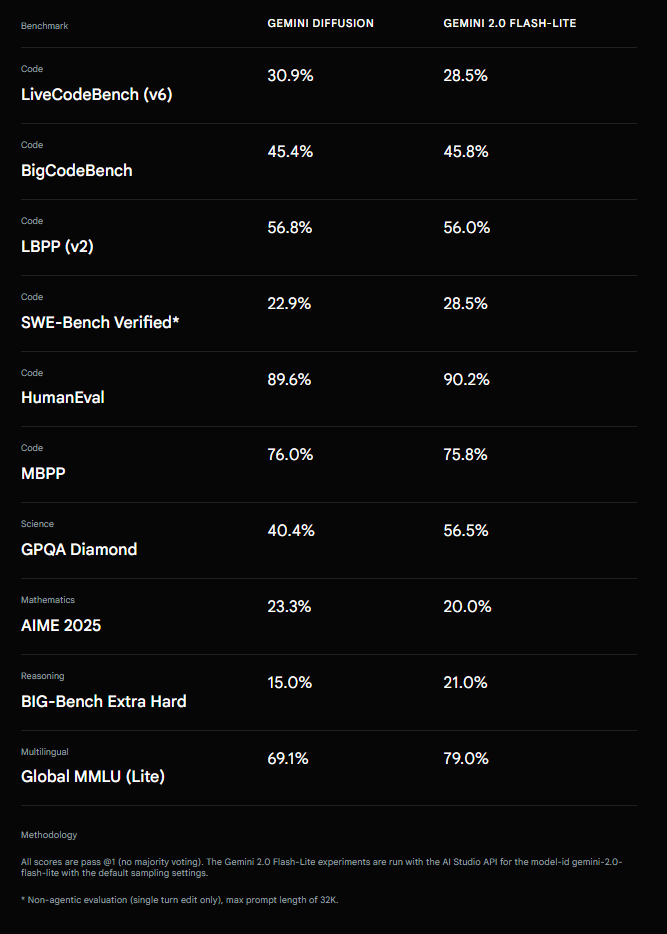
Jack Rae, Principal Scientist at Google Deepmind, called the results a "landmark moment." Until now, autoregressive models had consistently outperformed diffusion models in text quality, and it wasn't clear whether that gap could ever be closed. Rae credits the breakthrough to focused research and solving "a lot of" technical challenges.
Gemini Diffusion is currently available only as an experimental demo. Those interested can sign up for the waitlist.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.