Generative AI startup Odyssey demos interactive AI-generated video

Odyssey has released a research preview of a new kind of video: fully AI-generated sequences that respond to your input in real time.
The demo features what Odyssey calls interactive videos—AI-created image sequences that instantly react as you use a keyboard, controller, or smartphone to interact. The system relies on an autoregressive world model that figures out each next frame based on the current scene, your actions, and everything that's happened so far.
Video: via Odyssey
From passive video to interactive worlds
Odyssey describes its technology as a "world model," an AI system that doesn't just generate media, but creates dynamic environments you can interact with. This kind of model could become a training ground for agentic AI, letting systems learn and act independently inside simulated worlds, essentially learning from their own experience.
Unlike traditional video models, which generate an entire clip at once, Odyssey's world model updates the video frame by frame, constantly responding to your choices. According to Odyssey, its long-term goal is to simulate visuals and actions so realistically that they're indistinguishable from real life.
| World model | Video model |
|---|---|
| Predicts one frame at a time, reacting to what happens. | Generates a full video in one go. |
| Every future is possible. | The model knows the end from the start. |
| Fully interactive—responds instantly to user input at any time. | No interactivity—the clip plays out the same every time. |
Odyssey says the current demo is still raw and sometimes unstable, but already hints at what the company envisions for the future of AI-generated content. In Odyssey's view, instead of investing large amounts of time and money into producing interactive experiences, AI could eventually generate them on demand.
Stability through limited generalization
For the latest preview, Odyssey deliberately trained its model on a limited set of environments. The system was first taught on general video footage, then fine-tuned using video from a handful of well-documented scenes.
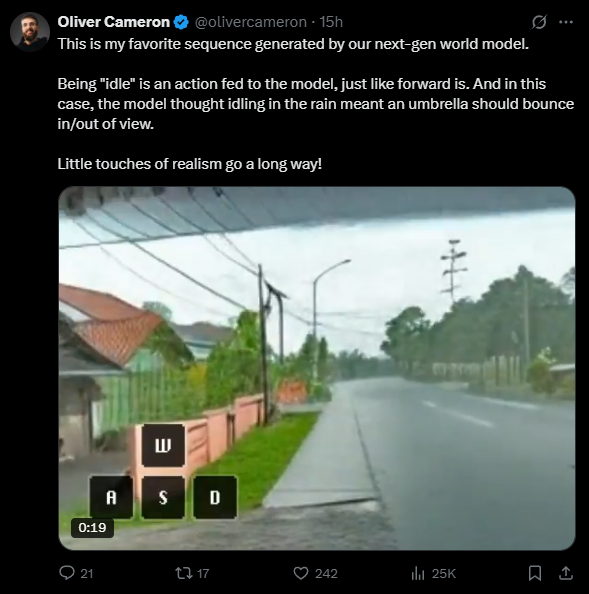
Co-founder Oliver Cameron says this focused training keeps the model stable and prevents it from slipping into illogical visuals. According to Cameron, a more generalist model would fall apart after 20 to 30 seconds, but the current version can deliver consistent video for about two and a half minutes. There's another trade-off besides less generalization: users can't yet freely look up or down, a limitation that results from prioritizing stability over total freedom.
According to Cameron, "every frame is absolutely generated by a diffusion model we've trained." The system processes user input instantly, producing a new frame every 40 milliseconds and streaming it back. Odyssey runs this on H100 GPU clusters in the US and EU. Under ideal conditions, latency is 40 milliseconds, and current costs range from one to two dollars per user hour, with prices expected to drop.
Odyssey is already working on a model with broader generalization and more realistic dynamics. Early versions show more diverse visual patterns, movement, and interactions, with better consistency over time.
A similar idea is being developed by Decart AI, whose Oasis project is a Minecraft-style game created in real time by AI. Their model, trained on video data, generates graphics, physics, and gameplay while players interact with mouse and keyboard. Oasis combines vision transformers with a diffusion model for stable visuals.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.