Three new methods show how Stable Diffusion or Imagen can be used for robotics training.
Large language models have been gaining traction in robotics over the past year, with Google showing several examples, including SayCan and Inner Monologue. These models bring extensive knowledge of the world, rudimentary logic capabilities, or translations from natural language to code to robotics, allowing for better planning with feedback or control via voice commands.
With diffusion models, researchers are now applying the next class of large AI models to robotics. With those generative image models, they are trying to solve one of the central problems of robot training: the lack of training data.
Data multiplication with generative image models
Collecting data in robotics is extremely time-consuming. A Google dataset of 130,000 robot demonstrations, for example, was collected from 13 robots over a 17-month period. So researchers are looking for ways to speed up the process. One of them is Sim2Real, meaning training in a simulation. However, real-world training data is still considered the gold standard.
Infinite training data thanks to diffusion models? Google shows how that might be possible. | Video: Google
Can this data be augmented with generative AI models? That's the question several research groups are asking, and in several papers, they show that augmenting training data with diffusion models does indeed lead to better robots.
To do this, the teams use existing footage and generate numerous variations with different details: they change the sink, a table becomes a kitchen shelf, a never-before-seen object stands next to a can, or the object a robot arm is grasping in the scene changes.
ROSIE, GenAug, CACTI and DALL-E-Bot show promising results
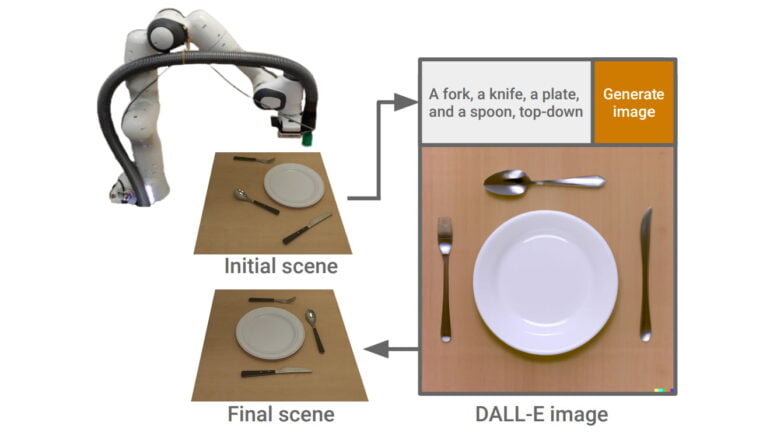
One of the first papers to use diffusion models for robotics is called DALL-E-Bot and was presented back in November 2022. Researchers at Imperial College London modified simple kitchen images using OpenAI DALL-E 2 to train a robotic arm.
They used DALL-E 2 to generate a new desired arrangement of objects from an existing scene, such as a plate and cutlery, via text description, which then served as a template for the robot to perform its task.

Now, three other groups have presented different methods. Two of them - "Robot Learning with Semantically Imagined Experience" (ROSIE) from Google and CACTI from researchers at Columbia University, Carnegie Mellon University, and Meta AI - use diffusion models to augment training data with photorealistic changes.
The third project - GenAug from the University of Washington and also from Meta - is based on a similar idea, but uses depth information to modify or generate existing and new objects in scenes with a depth-guided diffusion model. The team hopes this will provide a more accurate representation of the original scene.
Video: Meta
All methods show that augmenting the data leads to more robust robots that can better handle previously unseen objects. CACTI relies on Stable Diffusion for augmentation. Google, on the other hand, uses its own Imagen model and a huge dataset of 130,000 demonstrations to train an RT-1 robot model. Google also demonstrates in real-world trials that the robots can perform tasks that they have only seen through the lens of image synthesis, such as picking up objects that they have only seen in images manipulated by Imagen.
The "Bitter Lesson 2.0" and Foundation Models in robotics
While the diffusion models produce good results, they require more computing power than other architectures. According to Google, this limits the cost-effective use of these models for very large data augmentations. In addition, the methods presented change the appearance of objects or entire scenes, but do not generate new movements - these still need to be collected through human demonstrations.
Google sees potential in simulation data as a source for large datasets of robot motion and believes that sophisticated diffusion models could be replaced by models like Muse that are about ten times more efficient.
Google robotics researcher and Stanford professor Karol Hausman sees the three methods presented as an example of what he calls the "Bitter Lesson 2.0," according to which robotics should look to trends outside of robotics for new methods of building general-purpose robots. The "Bitter Lesson" comes from an essay by AI pioneer Richard Sutton.
Bitter lesson by @RichardSSutton is one of the most insightful essays on AI development of the last decades.
Recently, given our progress in robotics, I've been trying to predict what the next bitter lesson will be in robotics and how we can prevent it today.
Let me explain ? pic.twitter.com/0TeiRykOlU
- Karol Hausman (@hausman_k) January 9, 2023
According to Hausman, this trend is foundation models, meaning large, pre-trained AI models such as GPT-3, PaLM, or Stable Diffusion. He summarizes his view as follows: "To summarize, I believe that the next bitter lesson (in 70 years) will be: 'The biggest lesson that can be read from 70 years of AI research is that general methods that leverage foundation models are ultimately the most effective'".
Experiments so far with language and image models seem to prove him right. In the future, more foundation models may emerge that provide new data modalities for robot training.