
When language models are scaled, new abilities sporadically appear that are not found in smaller models. A research paper examines this effect.
In various disciplines such as philosophy, the classical sciences, cognitive science, systems theory, and even in art, emergence refers to the situation in which an object of study exhibits properties that its individual elements do not possess by themselves. These are, for example, behaviors or abilities that only emerge through the interaction of the individual parts.
The term comes from the Latin emergere, a word that translates as "appear," "arrive" or "rising up." Some theories consider consciousness, for example, to be an emergent property of biological brains. An example of emergence in physical systems is the emergence of complex symmetrical and fractal patterns in snowflakes.
Large language models exhibit emergent abilites
Large language models such as OpenAI's GPT-3 have recently defined natural language processing (NLP) and enabled large leaps in performance. These models showed that scaling language models by using more training data and parameters leads to better performance on NLP tasks. By studying "scaling laws", the researchers were able to systematically predict the effects of scaling on performance in numerous instances.
With scaling, however, came the realization that model performance on certain tasks does not increase continuously with scaling. The observed jumps in performance on such tasks thus cannot always be predicted in advance. On the contrary, abilities are found in large language models that are not found in smaller models.
A new paper by researchers at Google Research, Stanford University, UNC Chapel Hill, and Deepmind is now exploring these emerging abilities in large-scale language models.
Researchers study the unpredictable phenomenon of emerging abilities
According to the team, these emergent abilities include, for example, the ability to control language model outputs with few-shot prompting or to perform basic mathematical calculations such as addition and subtraction with three or multiplication with two digits.
In these and other cases, it can be shown that when visualized using a scaling curve, performance is nearly random at the beginning, and at a certain critical threshold of the model scale, performance jumps well above random.
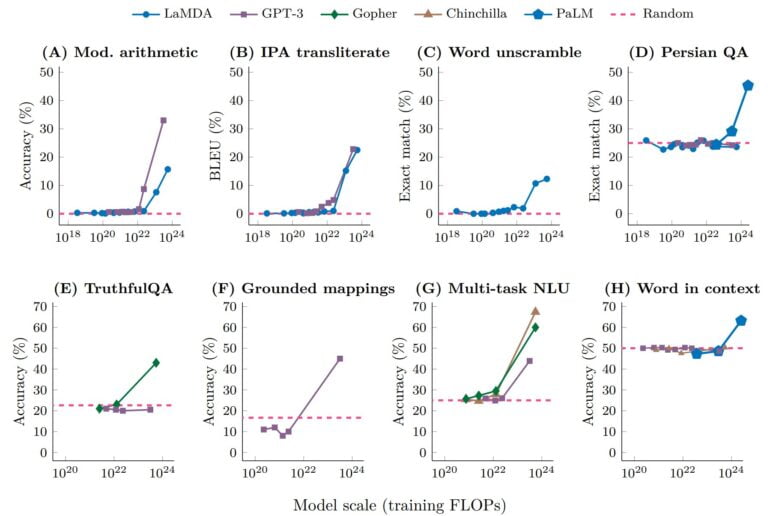
This qualitative change is also known as a phase transition: A dramatic change in overall behavior that could not have been predicted when the system was studied at a smaller scale.
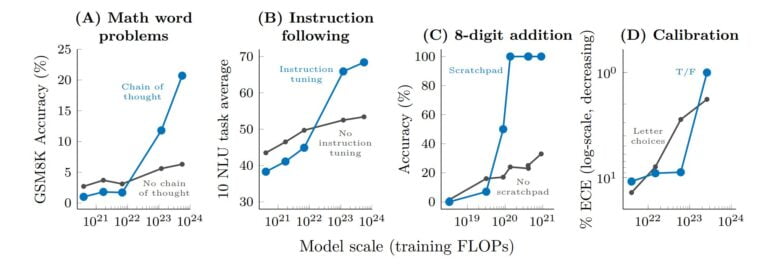
Beyond few-shot prompting, there are other prompting and fine-tuning strategies that improve the capabilities of large language models. One example is chain-of-thought prompting, which performs inference more reliably.
For some of these methods, the researchers also observe emergent effects: In smaller models, performance remains the same or even deteriorates despite the use of a method. Only in larger models do the methods lead to performance leaps.
Emergent abilities remain unexplained for now
In their paper, the researchers also refer to various explanations for the phenomenon of emergent abilities in large language models. However, they conclude that it cannot yet be explained conclusively.
In addition to scaling model size and datasets, in some cases, smaller models with more modern architectures, higher quality data, or improved training procedures can develop similar capabilities. So scaling is not the only factor that enables a new ability.
However, it is often the scaling that shows that such emergent abilities are possible in the first place. The 175-billion model GPT-3, for example, had not shown above-chance performance on one-shot prompts. Some researchers suspected the cause to be the model architecture used by GPT-3 and the training objective. Later, however, the 540-billion-parameter model PaLM showed that scaling alone can be sufficient to achieve above-average performance on this task without changing the architecture fundamentally.
The emergence of new abilities, therefore, raises whether further scaling will enable larger language models with novel abilities. According to the researchers, there are dozens of tasks in the BIG-Bench benchmark for NLP that no large language model has yet cracked - many of which involve abstract reasoning, such as chess or advanced mathematics.
The team sees the following points as relevant for future research:
- further model scaling
- improved model architectures and training
- data scaling
- better techniques for and understanding of prompting
- frontier tasks at the limit of the capability of current language models
- understanding emergence
We have discussed emergent abilities of language models, for which meaningful performance has only been thus far observed at a certain computational scale. Emergent abilities can span a variety of language models, task types, and experimental scenarios. Such abilities are a recently discovered outcome of scaling up language models, and the questions of how they emerge and whether more scaling will enable further emergent abilities seem to be important future research directions for the field of NLP.
From the paper




