Google Gemini Pro falls behind free ChatGPT, says study
A recent study by Carnegie Mellon University (CMU) shows that Google's latest large language model, Gemini Pro, lags behind GPT-3.5 and far behind GPT-4 in benchmarks.
The results contradict the information provided by Google at the Gemini presentation. They highlight the need for neutral benchmarking institutions or processes.
Gemini Pro loses out to GPT-3.5 in benchmarks
Google DeepMind's Gemini is the latest in a series of major language models. The Gemini team claims that the "Ultra" version, due out early next year, will outperform GPT-4 on various tasks. But Google has already fiddled with the presentation of Ultra's benchmark results.
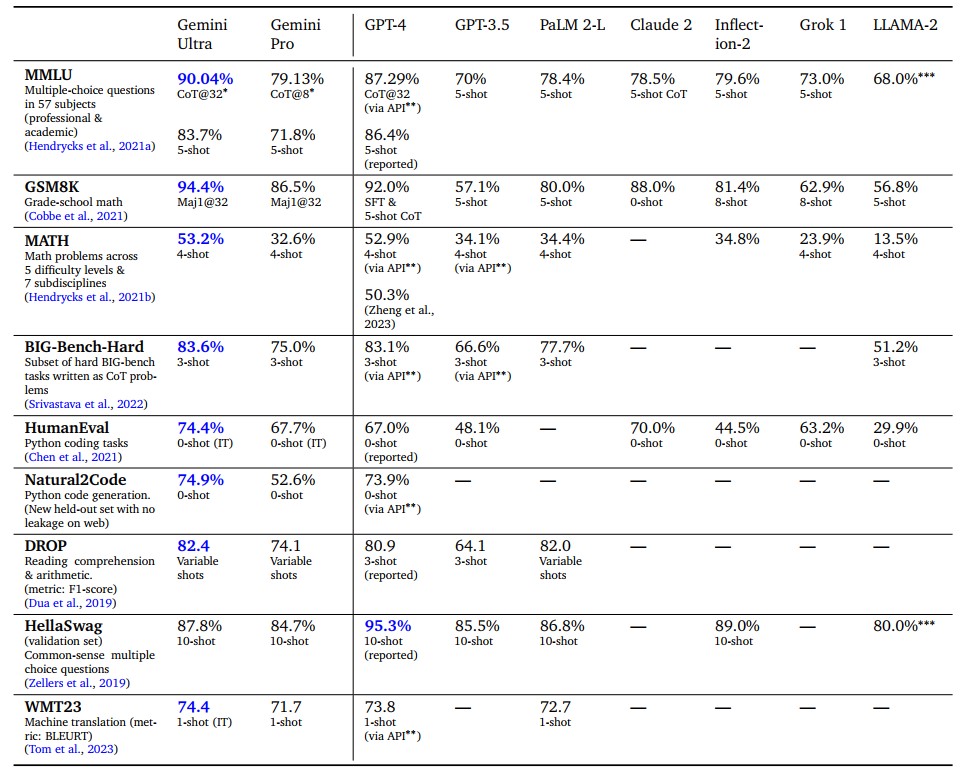
Google also claims that Gemini Pro, which is now available and powers the Bard chatbot, is comparable to or better than OpenAI's GPT-3.5. However, the CMU study shows that Gemini Pro performed worse than OpenAI GPT-3.5 Turbo on all benchmarks tested at the time of the study.
Benchmark discrepancies
Some discrepancies may be due to Google's protection mechanisms, which caused the model to not answer some questions in the MMLU assessment. These missing answers were scored as incorrect for each model.
However, the researchers also found that Gemini Pro performed worse in the area of basic mathematical reasoning, which is required for tasks in formal logic and elementary mathematics.
In terms of subject categories, Gemini Pro only outperformed GPT-3.5 in Security Studies and High School Microeconomics. It trailed in all other categories.

Google reported Gemini Pro's MMLU 5-Shot and Chain of Thought (CoT) scores as 71.8 and 79.13, respectively, while the CMU researchers reported 64.1 and 60.6, respectively. The Big Bench Hard benchmark score reported by Google was 75.0, while the CMU researchers found it to be 65.6. These are significant differences, the origin of which is still unclear.
Need for neutral model benchmarking
The results of the study show that the exclusive use of self-reported benchmarks from large companies is not a reliable measure of LLM performance.
They also show that OpenAI with GPT-3.5, the model behind the free ChatGPT, is still well ahead of Google and thus Google Bard. And they do not bode well for the first neutral benchmarks of Gemini Ultra, which - according to Google - should be better than GPT-4.
In any case, it is not good news for the AI industry that Google has not even been able to reliably catch up with OpenAI despite its best efforts.
The Gemini Pro model, which is comparable to GPT 3.5 Turbo in model size and class, generally achieves accuracy that is comparable but somewhat inferior to GPT 3.5 Turbo, and much worse than GPT 4. It outperforms Mixtral on every task that we examined.
In particular, we find that Gemini Pro was somewhat less performant than GPT 3.5 Turbo on average, but in particular had issues of bias to response order in multiple-choice questions (Note: When the model had to choose between A, B, C, and D, it usually chose D), mathematical reasoning with large digits, premature termination of agentive tasks, as well as failed responses due to aggressive content filtering.
On the other hand, there were bright points: Gemini performed better than GPT 3.5 Turbo on particularly long and complex reasoning tasks, and also was adept multilingually in tasks where responses were not filtered.
From the paper
The study probably also shows the first MMLU benchmark for GPT-4 Turbo. According to this, the latest OpenAI model is significantly behind the original GPT-4 in the important language comprehension benchmark (80.48 GPT-4 Turbo vs. 86.4 GPT-4).
This result is partially confirmed by the first reports from real-world use. On the other hand, the GPT-4 Turbo is currently by far the best-rated model in the chatbot arena. This shows that benchmarks are only of limited value.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.