Google releases new Gemma 3 open model family
Google Deepmind has unveiled Gemma 3, a new generation of open AI models designed to deliver high performance with a relatively small footprint, making them suitable for running on individual GPUs or TPUs.
The Gemma 3 family includes four models ranging from 1 to 27 billion parameters. Despite their compact size, these models outperform much larger LLMs like Llama-405B and DeepSeek-V3 in initial tests, according to Google Deepmind.
The models can handle more than 140 languages, with 35 requiring no additional training. They process text, images (except for the 1B version), and short videos using a 128,000-token context window. Google says their function calling and structured output capabilities make them well-suited for agentic tasks.

All models underwent distillation training followed by specialized post-training using various reinforcement learning approaches. These techniques specifically target improvements in mathematics, chat functionality, instruction following, and multilingual communication.
Making LLMs more efficient
For the first time, Google is officially offering quantized versions that reduce memory and computing requirements while maintaining accuracy. The company says Gemma 3 will reproduce less verbatim text than previous versions and avoid reproducing personal data.
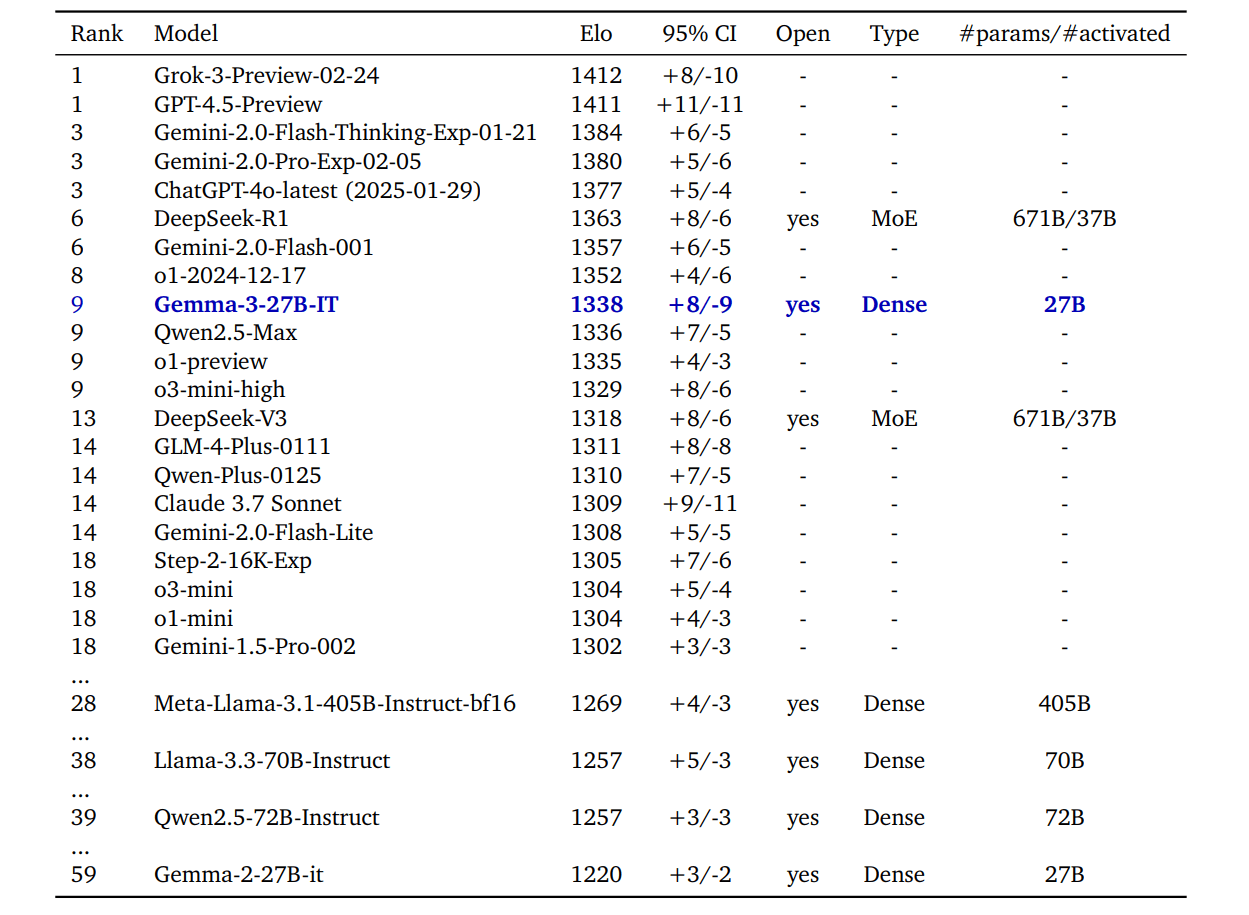
Human evaluators in the chatbot arena gave Gemma 3-27B-IT an Elo score of 1338, ranking it among the top 10 AI models. The smaller 4B model performs surprisingly well, matching the capabilities of the larger Gemma 2-27B-IT. The 27B version shows similar performance to Gemini 1.5-Pro across many benchmark tests.
Alongside the multimodal Gemma models, Google introduced ShieldGemma 2, a specialized 4-billion-parameter security checker designed to identify dangerous content, explicit material, and depictions of violence in images.

Gemma 3 models are available through Hugging Face, Kaggle, and Google AI Studio. They support common frameworks including PyTorch, JAX, and Keras. Academics can access $10,000 in cloud credits through the Gemma 3 Academic Program. The models run on NVIDIA GPUs, Google Cloud TPUs, and AMD GPUs, with Gemma.cpp available for CPU use.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.