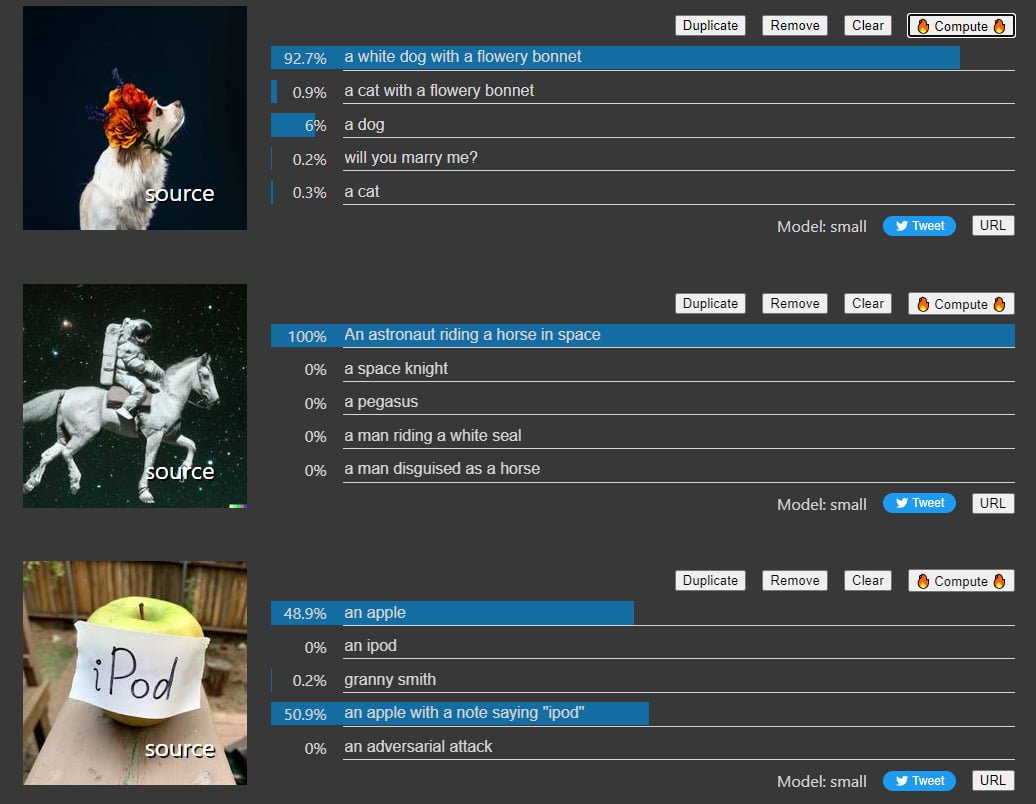
Google demonstrates impressive artificial intelligence image analysis: the multimodal trained LiT model outperforms OpenAI's CLIP.
The combination of images and text descriptions, usually pulled en masse from the Internet, has proven to be a powerful resource for artificial intelligence training.
Instead of relying on manually crafted image databases like ImageNet, where people search numerous images for each category like dog, cat, or table, newer image analysis models rely on comparatively unstructured masses of images and text. They learn multimodally and self-monitored. A particularly prominent example is OpenAI's CLIP, which is used, for example, in the new DALL-E 2.
These self-supervised trained AI models have one major advantage: they learn much more robust representations of visual categories, since they do not have to rely on the categorizations manually identified by humans.
Thus, they can be easily used for numerous image analysis tasks without further AI training. In contrast, models trained with ImageNet often require fine-tuning with additional data sets for each new task.
Google combines image and language understanding
However, multimodal models still have two problems: there are significantly more images without text descriptions than those with - researchers must therefore forgo large amounts of potentially useful data in training.
In practice, this leads to the second problem: Although multimodal models are more robust, they do not achieve the accuracy of traditional models trained only with image data in the ImageNet benchmark, for example.
Google researchers are now presenting a method called "Locked-Image Tuning" (LiT) that can retroactively transform such large image analysis models into multimodal models.
This method aims to combine the best of both worlds: a multimodal model with robust image analysis capabilities that does not need to be re-trained for new tasks, yet still approaches the accuracy of specialized models.

Google's LiT trains only the text encoder
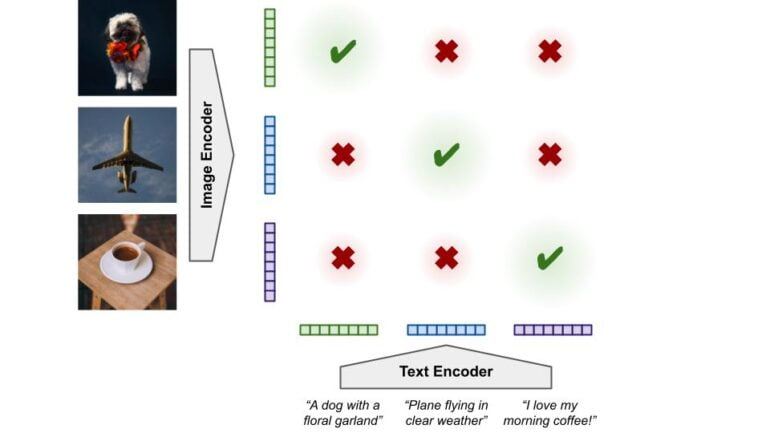
During multimodal training, an image encoder and a text encoder learn representations for images and text, respectively. Each image representation should be close to the representation of the corresponding text, but different from the representation of other texts in the data and vice versa.
In the training process, the encoders must therefore simultaneously learn the representations and their mapping to those of the second encoder.
Google is pursuing a different approach with LiT: A model pre-trained with three billion images serves as the image encoder, whose parameters are subsequently frozen in multimodal training. In this way, the image encoder and its learned representations are not changed.
Video: Google
The text encoder then learns during training to adapt its learned text representations to those of the image encoder. The training data for this step includes a private dataset of four billion images with associated text that the team collected.
Any pre-trained image model can be used as an image encoder. Google achieves the highest accuracy with its internally developed Vision Transformer.
Google's LiT beats OpenAI's CLIP
The model trained with LiT achieves 84.5 percent accuracy in the ImageNet benchmark and 81.1 percent accuracy in the more sophisticated ObjectNet benchmark without additional ImageNet training.
The current best value in ImageNet is 90.94 percent; CLIP achieved 76.2 percent. In the ObjectNet benchmark, the strongest version of CLIP achieved 72.3 percent accuracy.
Video: Google
Google's model surpasses OpenAI's CLIP in all benchmarks thanks to the pre-trained image encoder. The researchers also show that LiT still performs well even with publicly available datasets - though accuracy drops to 75.7 percent for ImageNet.
They also say the method allows for much more robust results even with less data. For example, LiT models trained with 24 million publicly available image-text pairs achieve the same performance as earlier models trained with 400 million image-text pairs from private data.
Google provides an interactive LiT demo where you can try out the capabilities of the LiT model based on a vision transformer.