Google's Nested Learning aims to stop LLMs from catastrophic forgetting

Google Research has introduced "nested learning," a new way to design AI models that aims to mitigate or even avoid "catastrophic forgetting" and support continuous learning.
In their NeurIPS 2025 paper, Google researchers highlight a core problem: large language models can't build new long-term memories after training. After training, these models only keep what's in their current context window or from pretraining. Expanding the window or retraining just delays the problem, like treating amnesia with a bigger notepad.
Current models are mostly static after pretraining. They can perform learned tasks but can’t pick up new abilities beyond their context, leading to so-called catastrophic forgetting. More updates make it worse.
How nested learning borrows from the brain
Like many machine learning advances, nested learning is inspired by neuroscience. The brain runs at different speeds: fast circuits handle the present, slower ones consolidate important patterns into long-term memory.
Most experiences fade quickly; only a few become lasting memories, thanks to neuroplasticity—the brain’s ability to rewire itself while preserving essential information. The authors contrast this with current LLMs, whose knowledge remains limited to their context window or static pretraining.

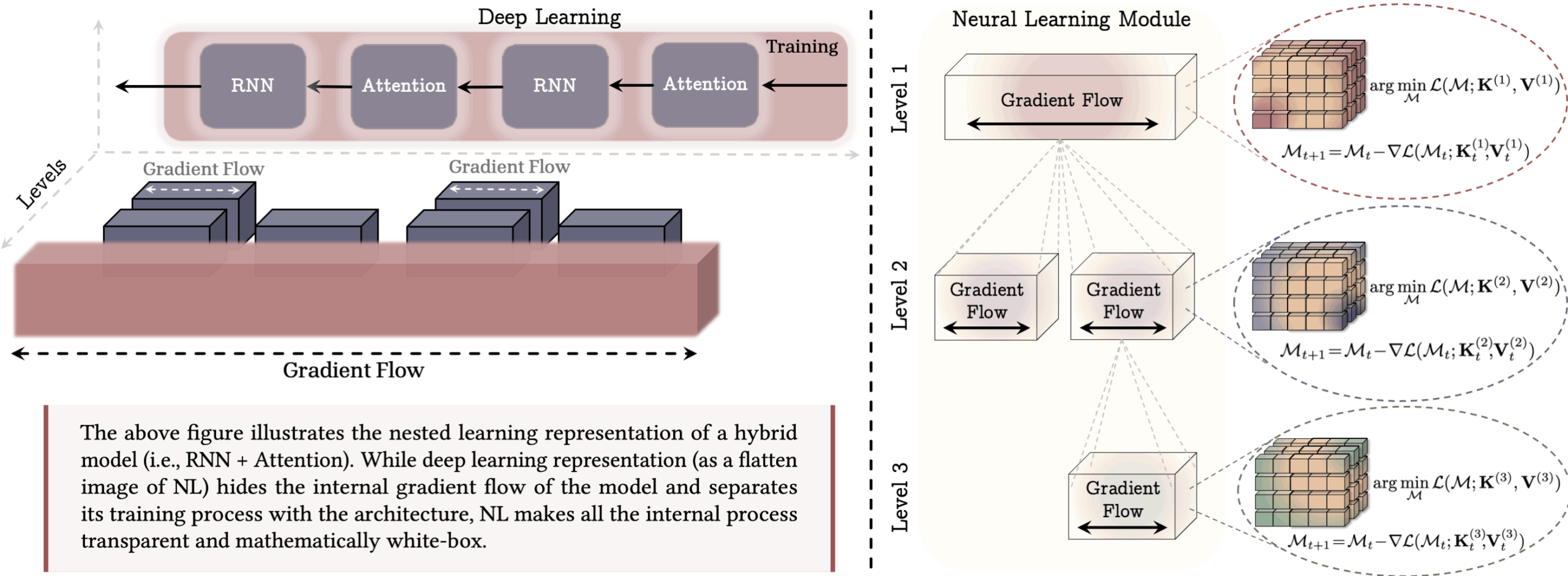
Nested learning treats every part of an AI model—including the optimizer and training algorithm—as memory. Backpropagation stores links between data and errors, and the optimizer's state, like momentum, acts as memory too. The Continuum Memory System (CMS) splits memory into modules that update at different rates, giving the model temporal depth.
HOPE: Nested Learning in practice
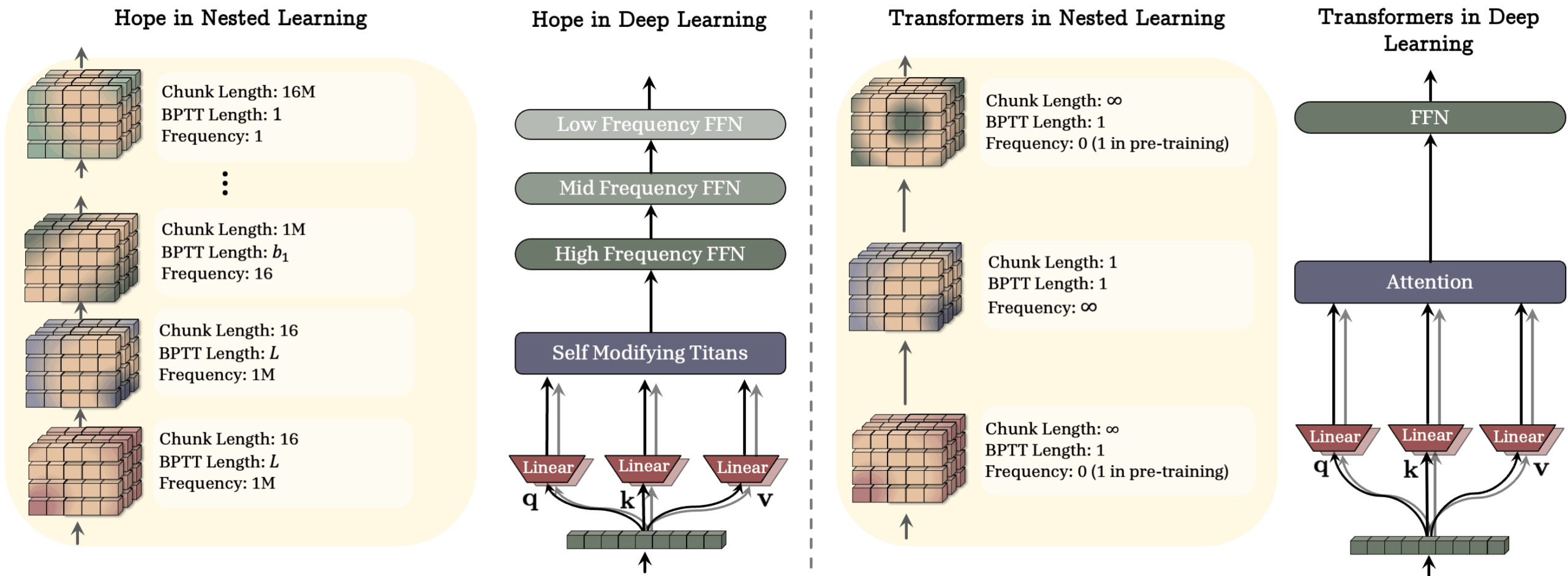
Google's HOPE architecture puts this to work. HOPE uses long-term memory modules called Titans, which store information based on how surprising it is to the model. It layers different types of memory and uses CMS blocks for larger context windows. Fast layers process live input, slower layers distill what's important for long-term storage, and the system can adapt its update rules as it learns. This goes beyond the typical “pretrain and freeze” model.
The team tested HOPE on language modeling and reasoning. With models at 1.3 billion parameters trained on 100 billion tokens, HOPE outperformed Transformer++ and newer models like RetNet and DeltaNet.
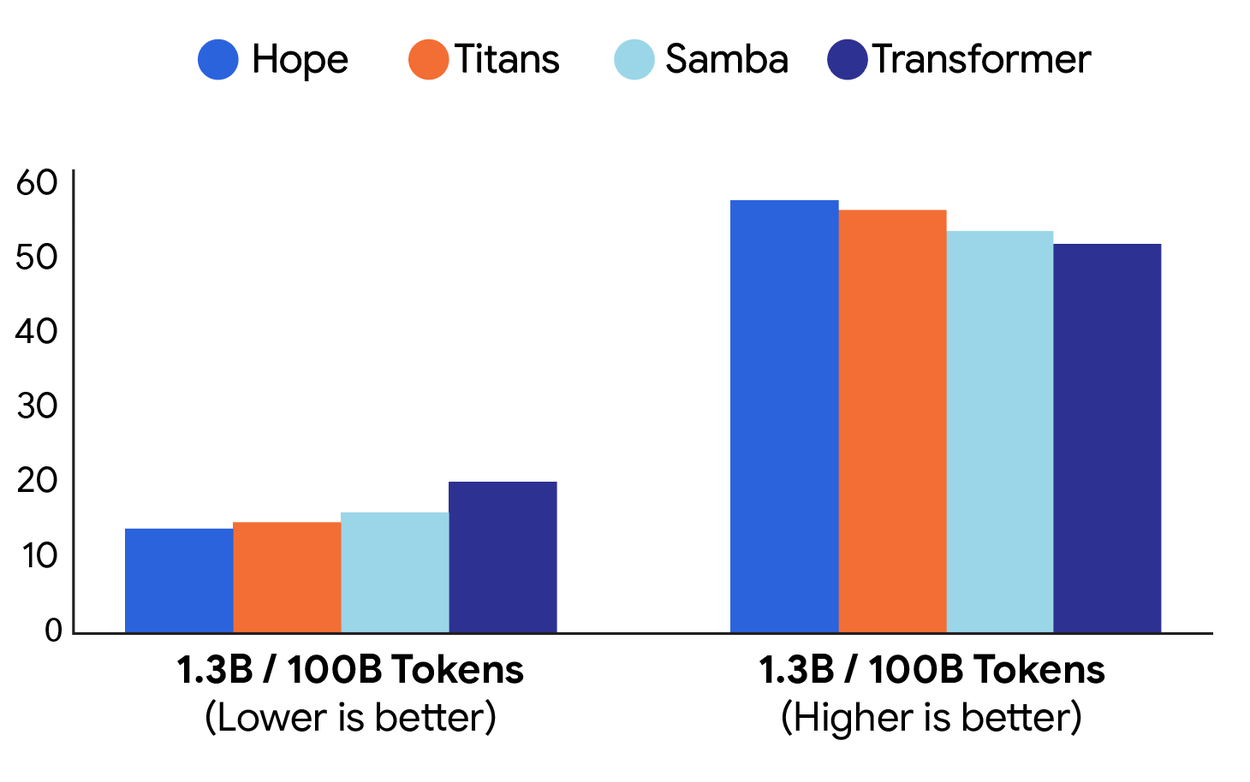
HOPE also performed better in long-context and needle-in-a-haystack tests, where the model has to find something specific in a large pile of text. Tests ranged from 340 million to 1.3 billion parameters. HOPE’s gains were consistent, and the authors say it can outperform both transformers and modern recurrent networks. An independent reproduction is on Github.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.