EleutherAI releases GPT-NeoX-20B, a 20 billion parameter open-source language model that comes close to OpenAI's largest GPT-3 variant in benchmarks.
EleutherAI is an independent research collective founded in July 2020 by Connor Leahy, Leo Gao, and Sid Black focused on alignment for artificial intelligence, scaling, and open-source AI research.
The now-grown group of AI researchers, who collaborate with each other via Discord and GitHub, is best known for its work with language models, among other AI projects. The group is working on open source alternatives to OpenAI's GPT-3, a highly regulated, high-performance language model available exclusively through OpenAI's API or through Microsoft services.
In early 2021, the collective announced the development of several language models, some trained on Google's TPU chips and larger variants trained on CoreWeave GPU servers.
In March 2021, EleutherAI released two GPT-Neo variants with 1.3 billion and 2.7 billion parameters. Then in July 2021, the group released GPT-J, a six-billion-parameter model trained on EleutherAI's own nearly 800-gigabyte "The Pile" language dataset that matches the performance of GPT-3's similarly sized Curie model.
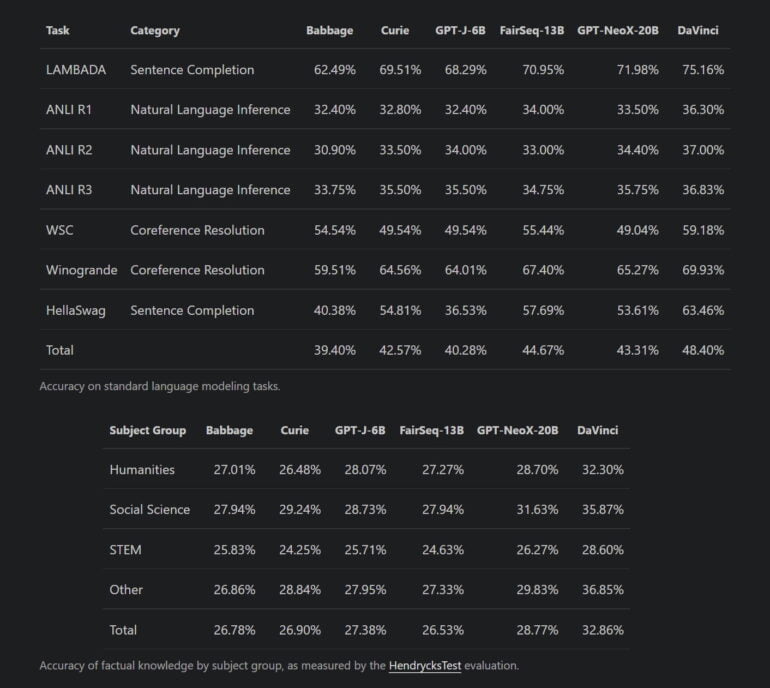
GPT-NeoX-20B comes close to GPT-3 DaVinci
Now EleutherAI is releasing GPT-NeoX-20B, the first model trained on CoreWeave GPUs using the internally developed GPT-NeoX framework. The 20-billion-parameter model was also trained with The Pile and outperformed the Curie model of GPT-3 by a few percentage points in the benchmarks performed by EleutherAI. The nearly 150-billion-parameter variant of GPT-3 "DaVinci" was outperformed by a few percentage points.
GPT-NeoX-20B will be available for download on The Eye starting Feb. 9. Interested parties can already test the model's capabilities on GooseAI, a platform for speech AI services that offers numerous GPT-3 alternatives.
GPT-NeoX-20B is a research object and not a product
EleutherAI notes, however, that GPT-NeoX-20B is a research object and advises against deploying it or any other model in a production environment without careful testing.
Interested parties are advised to study the training dataset used in detail. There is also a dedicated sub-channel #20b in EleutherAI's Discord where the model can be discussed.