
Benchmarks are a key driver of progress in AI. But they also have many shortcomings. The new GPT-Fathom benchmark suite aims to reduce some of these pitfalls.
Benchmarks allow AI developers to measure the performance of their models on a variety of tasks. In the case of language models, for example, answering knowledge questions or solving logic tasks. Depending on its performance, the model receives a score that can then be compared with the results of other models.
These benchmarking results form the basis for further research decisions and, ultimately, investments. They also provide information about the strengths and weaknesses of individual methods.
Although many LLM benchmarks and rankings exist, they often lack consistent parameters and specifications, such as prompting methods, or don't adequately account for prompt sensitivity.
This lack of consistency makes it difficult to compare or reproduce results across studies.
GPT-Fathom aims to bring structure to LLM benchmarking
Enter GPT-Fathom, an open-source evaluation kit for LLMs that addresses the above challenges. It was developed by researchers at ByteDance and the University of Illinois at Urbana-Champaign based on the existing OpenAI LLM benchmarking framework Evals.
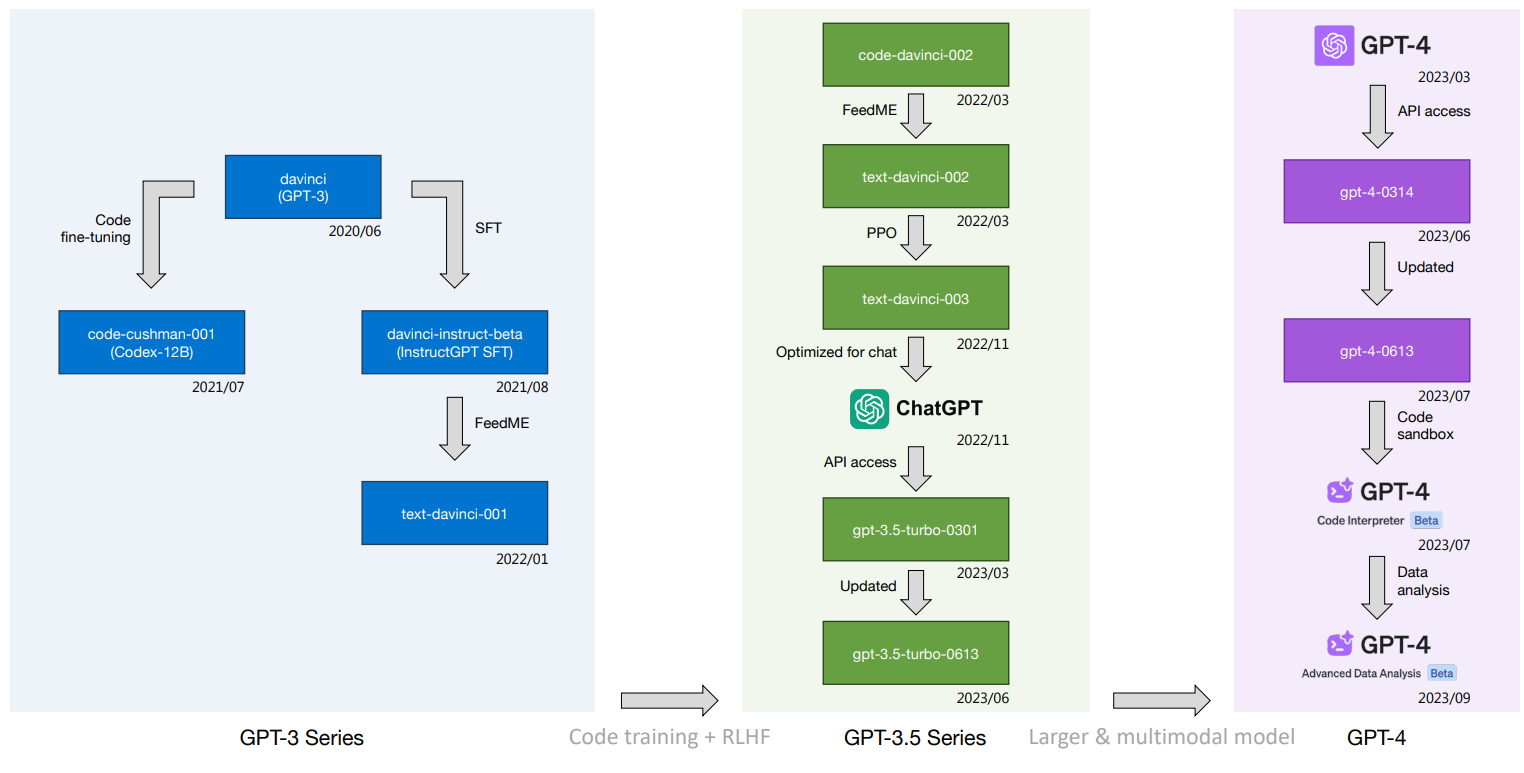
GPT-Fathom aims to address key issues in LLM evaluation, including inconsistent settings - such as the number of examples ("shots") in the prompt, incomplete collections of models and benchmarks, and insufficient consideration of the sensitivity of models to different prompting methods.
The team used its proprietary system to compare more than ten leading LLMs on more than 20 carefully curated benchmarks in seven skill categories, such as knowledge, logic, or programming, under consistent settings.
GPT-4 is clearly ahead
If you are a regular user of different LLMs, then the main result will not come as a surprise: GPT-4, the model behind the paid version of ChatGPT, "crushes" the competition in most benchmarks, the research team writes. GPT-4 also emerged as the winning model in a recently published benchmark on hallucinations.

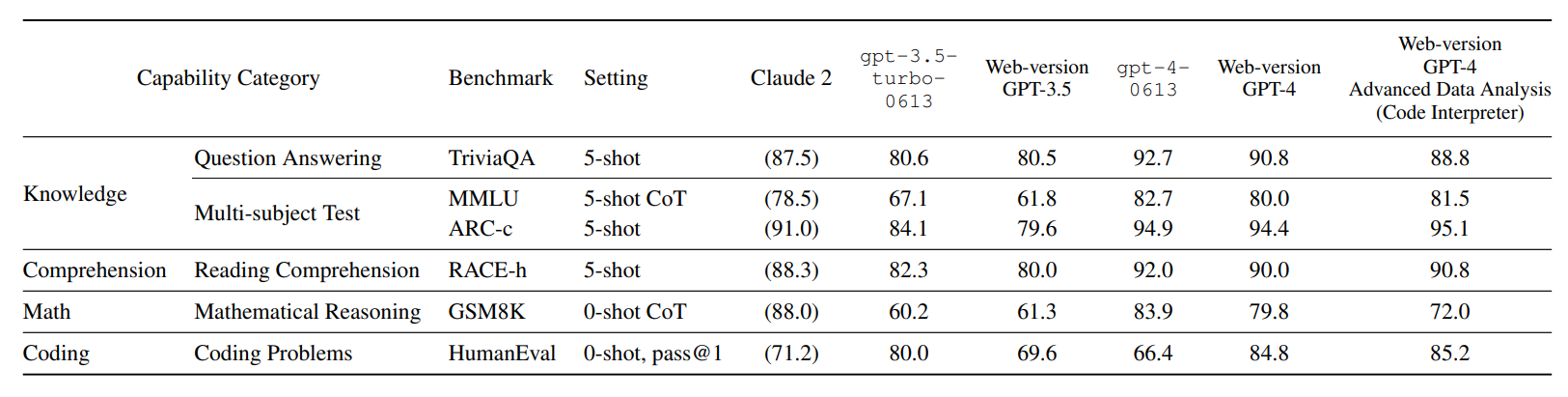
Compared to OpenAI's models in the GPT-3.5 family, GPT-4 is clearly ahead. The researchers also measured a significant performance difference in most benchmarks against Claude 2, which is currently ChatGPT's strongest competitor. Claude 2 can't match GPT-4, but it's still the most capable non-OpenAI model, the researchers conclude. GPT-4's Advanced Data Analysis model also outperforms the competition in coding.
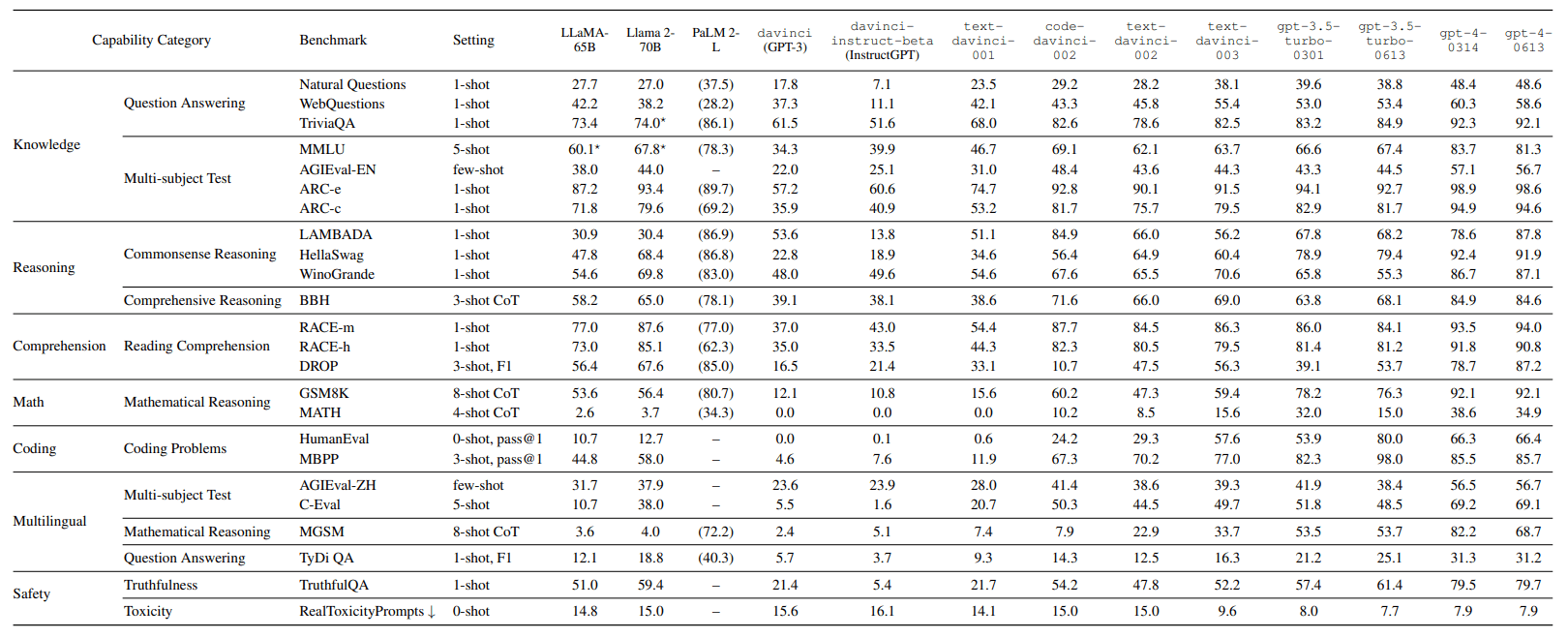
The current best-performing open-source model, Llama 2, outperforms its predecessor, Llama-65B, in most benchmarks, especially in the reasoning and comprehension tasks. Compared to gpt-3.5-turbo-0613, Llama 2-70B shows comparable performance in safety and even outperforms it in comprehension.
However, Llama 2-70B performs worse in other areas, especially in "Mathematics", "Coding", and "Multilingualism". These are known weaknesses of Meta's open-source model.
For the LLaMA-65B and Llama 2-70B models, the research team also claims to have measured a particular prompt sensitivity. For Llama 2-70B, even a small change in the prompt resulted in a drop in score from 74.0 to 55.5 points on the TriviaQA benchmark. The test assesses LLMs' reading comprehension and ability to answer questions.
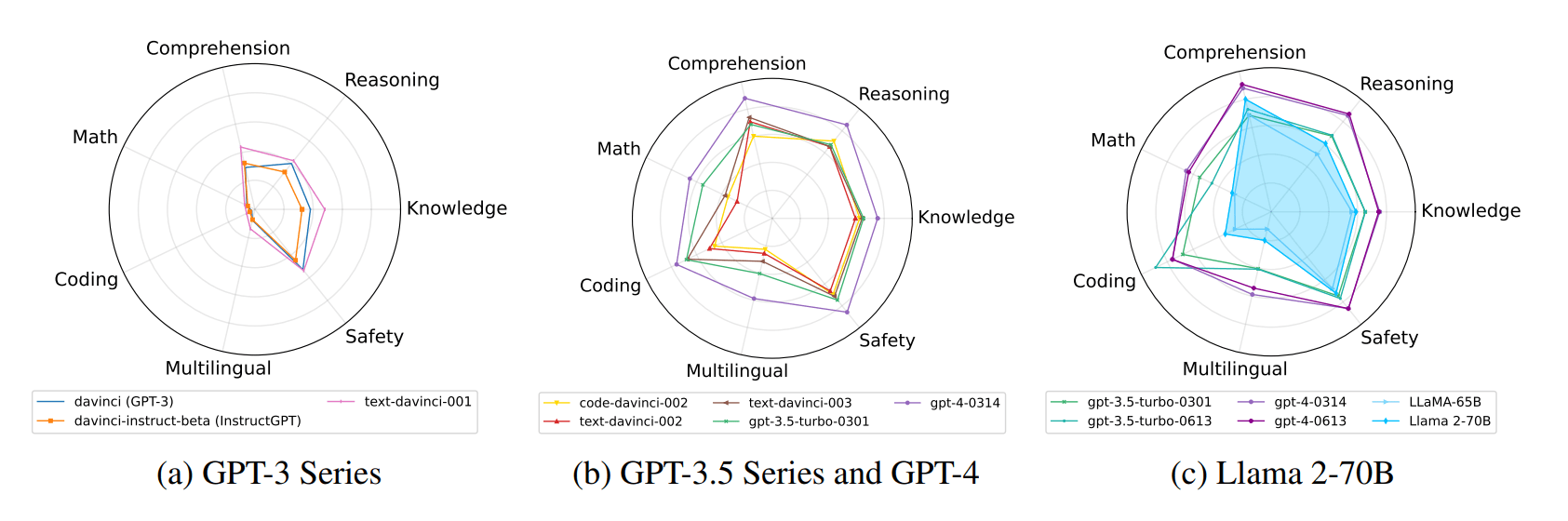
The research team also compared the evolution of OpenAI models from the early days of GPT-3 to GPT-4, and the result shows the huge leap from GPT-3 to its successors. Whether future models can make similar leaps is likely to be critical to the impact of large language models, especially on the job market.
The seesaw effect increases the complexity of LLM development
In the paper, the team also describes the "trade-off" or "seesaw" effect: A significant improvement in model performance in one area can lead to an unintended degradation of performance in another area.
For example, according to the team's measurements, "gpt-3.5-turbo-0613" significantly improved its performance on coding benchmarks compared to its predecessor, "gpt-3.5-turbo-0301". At the same time, however, the MATH score dropped significantly from 32.0 to 15.0.
A similar pattern can be seen for GPT-4: The model jump from gpt-4-0314 to gpt-4-0613 led to a strong performance increase on the text comprehension benchmark DROP (Discrete Reasoning Over Paragraphs).
At the same time, however, performance on the Mathematical Geometry Simple Math (MGSM) benchmark dropped significantly from 82.2 to 68.7. The benchmark measures simple computational tasks that require a basic understanding of number theory, arithmetic, and geometry.
According to the research team, these patterns underscore the complexity of training and optimizing LLMs. More research is needed to better understand these effects.




