GPT-4 passes Turing test and humans surprisingly often mistake other humans for AI

In a new study, human participants were unable to reliably distinguish whether they were chatting with a human or GPT-4. The results of the study raise new questions about the classic Turing test and its implications.
74 years after Alan Turing proposed his famous thought experiment comparing humans and machines, researchers have now conducted a randomized, controlled two-player variant of the Turing test with GPT-4. The result: In chats, human participants couldn't reliably recognize whether they were communicating with a human or the AI.
Before the test, the language models were set up with a detailed prompt to influence the responses, restricting typical behaviors and making the language models occasionally make spelling mistakes, for example.
GPT-4 was judged to be a human 54 percent - meaning half of the participants thought the model was human after a five-minute conversation. This made GPT-4 perform better than the older GPT-3.5 model (50 percent) and the simple, rule-based ELIZA reference system from the 1960s (22 percent). Only human participants achieved a higher success rate at 67 percent - so participants rated them as AI in just under a third of cases. Modern AI systems are thus able to credibly deceive humans. And: when humans know that AI can behave in a human-like manner, they will set their "human" bar so high that they will repeatedly exclude real humans.
Intelligence or not - language models can be deceptive
The researchers defined 50 percent as success on the Turing test, since participants then couldn't distinguish between human and machine better than chance. By this definition, GPT-4 passed the test. Participants didn't simply guess: When they thought GPT-4 was human, they did so with an average confidence of 73 percent.
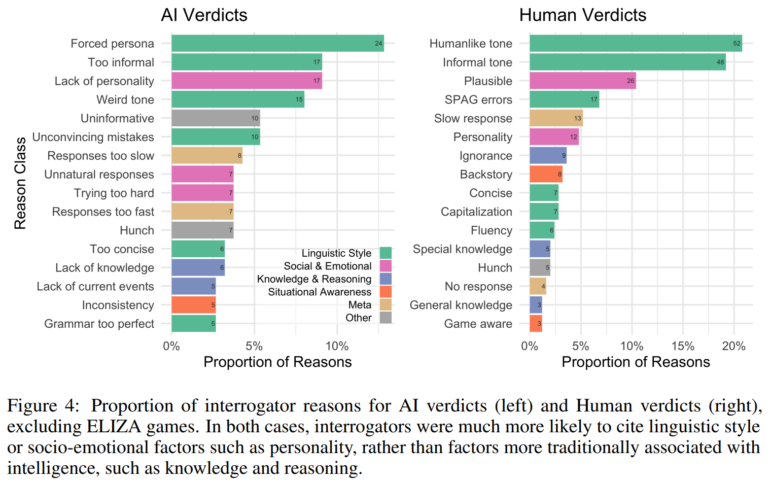
The Turing test is often described as a benchmark for machine intelligence. There was a lot of criticism of this: The test is too easy or too difficult, it doesn't really measure intelligence. The study results now provide empirical evidence of what the Turing test probably actually measures: Participants' strategies and rationales focused more on language style and socio-emotional factors than on knowledge and logic.
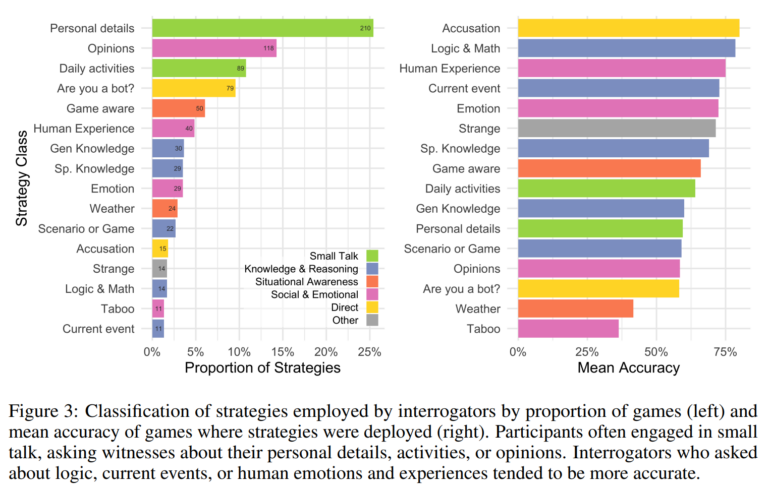
However, participants who asked about logic, current events, or human emotions and experiences were right more often on average.
"The results here likely set a lower bound on the potential for deception in more naturalistic contexts where, unlike the experimental setting, people may not be alert to the possibility of deception or exclusively focused on detecting it," the paper states. Systems that can reliably mimic humans could have far-reaching economic and social impacts, for example, by taking over customer contacts previously reserved for human employees.
But they could also mislead the public or their own human operators and undermine social trust in authentic human interactions, the scientists say.
The solution: A) is GPT-4, B) is human, C) is GPT-3.5, D) is ELIZA.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.