Guanaco is a ChatGPT competitor trained on a single GPU in one day

A new method named QLoRA enables the fine-tuning of large language models on a single GPU. Researchers used it to train Guanaco, a chatbot that reaches 99 % of ChatGPTs performance.
Researchers at the University of Washington present QLoRA (Quantized Low Rank Adapters), a method for fine-tuning large language models. Along with QLoRA, the team releases Guanaco, a family of chatbots based on Meta's LLaMA models. The largest Guanaco variant, with 65 billion parameters, achieves above 99 percent of the performance of ChatGPT (GPT-3.5-turbo) in a benchmark run with GPT-4.
Fine-tuning large language models is one of the most important techniques for improving their performance and training desired and undesired behaviors. However, this process is extremely computationally intensive for large models such as LLaMA 65B, requiring more than 780 gigabytes of GPU RAM in such cases. While the open-source community uses various quantization methods to reduce 16-bit models to 4-bit models, significantly reducing the memory required for inference, similar methods have not been available for fine-tuning.
QLoRA allows fine-tuning of 65 billion parameters LLM on a single GPU
With QLoRA, the team demonstrates a method that allows a model such as LLaMA to be quantized to 4 bits and low-rank adaptive weights (LoRAs) to be added and then trained by backpropagation. In this way, the method enables the fine-tuning of 4-bit models and reduces the memory requirement for a 65-billion-parameter model from over 780 gigabytes to less than 48 gigabytes of GPU memory - with the same result as fine-tuning a 16-bit model.
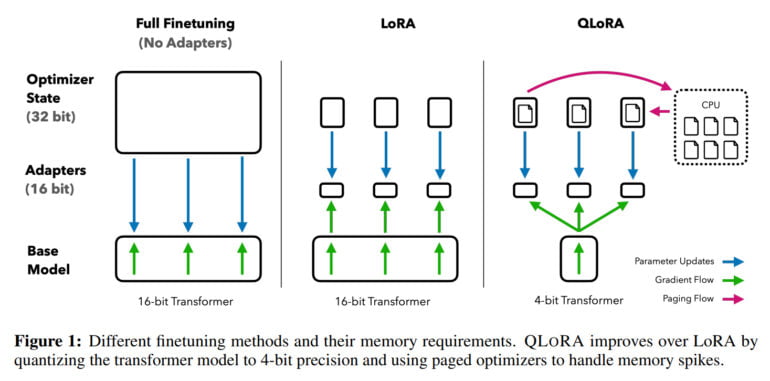
"This marks a significant shift in accessibility of LLM finetuning: now the largest publicly available models to date finetunable on a single GPU.," the team said.
To test QLoRA and the impact of different fine-tuning datasets, the team trained more than 1,000 models on eight different datasets. One key finding: the quality of the data is more important than its quantity for the task at hand. For example, models trained on OpenAssistant's 9,000 examples collected from humans are better chatbots than those trained on FLANv2's one million examples. For Guanaco, the team, therefore, relies on OpenAssistant data.
Open-source model Guanaco reaches ChatGPT level
Using QLoRA, the team trains the Guanaco family of models, with the second-best model achieving 97.8 percent of ChatGPT's performance with 33 billion parameters in a benchmark, while training it on a single consumer GPU in less than 12 hours. On a professional GPU, the team trains the largest model with 65 billion parameters at 99.3 percent of ChatGPT's performance in just 24 hours.
The smallest Guanaco model, with 7 billion parameters, requires only 5 gigabytes of GPU memory and outperforms the 26-gigabyte Alpaca model by more than 20 percentage points on the Vicuna benchmark.
In addition to QLoRA and Guanaco, the team also publishes the OpenAssistant benchmark, which pits models against each other in 953 prompt examples. The results can then be scored by humans or GPT-4. The Vicuna benchmark provides only 80.
Guanaco is bad at math, QLoRA could be used for mobile fine-tuning
The team cites math capabilities and the fact that 4-bit inference is currently very slow as limitations. Next, the team wants to improve inference and expects a speed gain of 8 to 16 times.
Since fine-tuning is an essential tool for turning large language models into ChatGPT-like chatbots, the team believes the QLoRA method will make fine-tuning more accessible - especially to researchers with fewer resources. That's a big win for the accessibility of cutting-edge technology in natural language processing, they say.
"QLORA can be seen as an equalizing factor that helps to close the resource gap between large corporations and small teams with consumer GPUs," the paper states. This also means that fine-tuning is possible via cloud services like Colab, as one person has already shown.
I can't believe I've just fine-tuned a 33B-parameter LLM on Google Colab in a few hours.😱
Insane announcement for any of you using open-source LLMs on normal GPUs! 🤯
A new paper has been released, QLoRA, which is nothing short of game-changing for the ability to train and… pic.twitter.com/Ye1zuH4gQD
— Itamar Golan 🤓 (@ItakGol) May 25, 2023
In addition to fine-tuning today's largest language models, the team sees applications for private models on mobile hardware. "QLoRA will also enable privacy-preserving fine-tuning on your phone. We estimate that you can fine-tune 3 million words each night with an iPhone 12 Plus. This means, soon we will have LLMs on phones which are specialized for each individual app," first author Tim Dettmers said on Twitter.
A demo of Guanaco-33B is available on Hugging Face. More information and code is available on GitHub. Since Guanaco is built on top of Meta's LLaMA, the model is not licensed for commercial use.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.