
Multimodal AI models can caption images and answer questions about them - but their answers don't always make sense. Can they learn from humans?
Vision-Language Models (VLMs) combine transformer-based language models with computer vision for image captioning, answering questions about them, or, conversely, judging how well an image description matches an image. There are different architectures with different capabilities, e.g. OpenAI's CLIP, Deepmind's Flamingo, the recently released MiniGPT-4, or Aleph Alpha's MAGMA.
Most VLMs today are based on a large language model that has not yet been aligned with human intent on a given task through methods such as instruction tuning and reinforcement learning with human feedback. As a result, the output of VLMs often does not match human rationales for specific responses. Now researchers from TU Darmstadt, Hessian.AI, the Center for Cognitive Science Darmstadt, Aleph Alpha, LAION, and the German Research Center for Artificial Intelligence demonstrate the alignment of VLMs with human feedback.
ILLUME aims to "rationalize" VLMs
The team calls the method ILLUME (InteractiveLy RationaLizing Vision-LangUage ModEls), a fine-tuning scheme "to transfer reasoning capabilities from language models to vision-language models." The method is based on three steps: (1) The VLM generates several rationales for an answer to a question about an image, e.g., "Q: What type of animal is in the picture? - A: giraffe, seeing that...".

(2) Human annotators select the appropriate reasons from the given options, e.g. "...it has a long neck". (3) The VLM is fine-tuned for all selected rationales that have at least one matching explanation.
The process is repeated until there is an appropriate rationale for all cases, or no further progress is made.
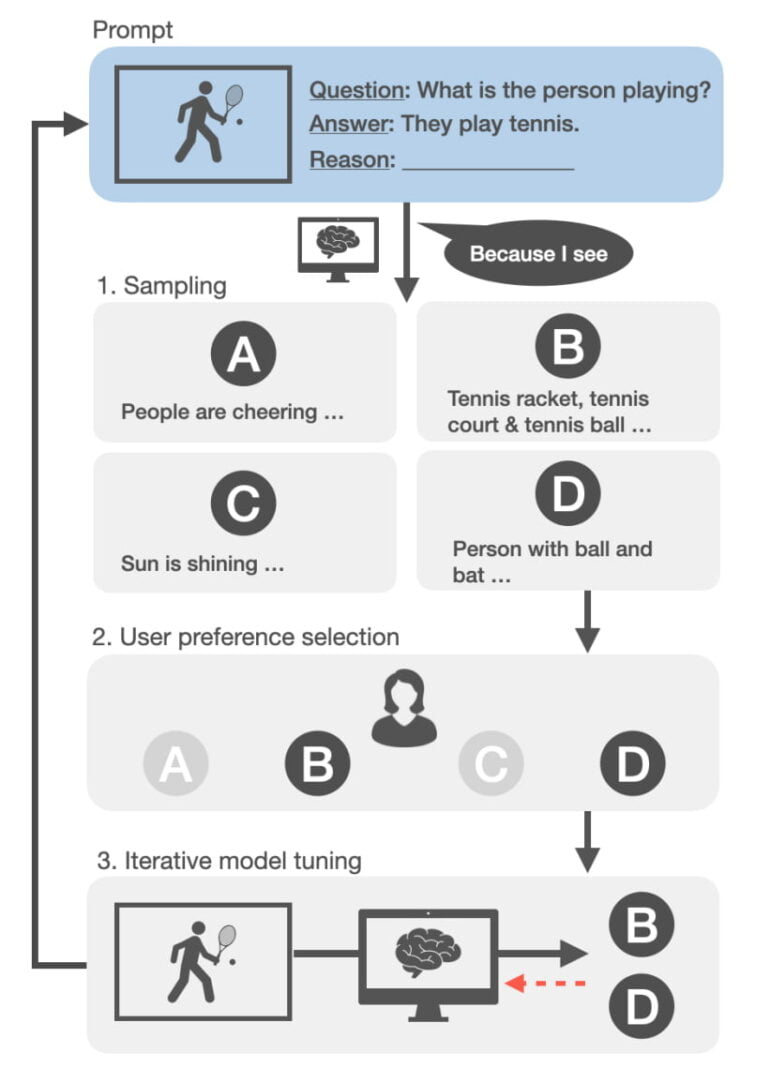
According to the team, human feedback could theoretically be replaced by a reward model, as in the case of ChatGPT, but "this could require prior expensive human labor and is inherently limited."
ILLUME significantly reduces required training data
The process improves the model's performance based solely on examples generated by the model and selected through human feedback. It interactively aligns the model to human preferences while "gradually carving out rationalization capabilities." Empirical evaluation by the team shows that ILLUME uncovers and reinforces latent capabilities of the language model, resulting in better overall reasoning.

A major advantage of the method is that the team was able to show that a MAGMA-VLM trained with ILLUME can approach the performance of models trained with up to five times more ground truth fine-tuning data.
For all its success, however, the method is unable to extract from the underlying language models capabilities that they did not already possess. "Current LMs appear incapable of inferring logical reasoning from a few training examples. Therefore, VLMs bootstrapped from LMs struggle to transfer logical reasoning capabilities without major extensions. Instead, we argue that the approach of training and evaluating logical reasoning as a pure text generation task may be inherently flawed. ".
All information and code for ILLUME is available on GitHub




