Junk data from X makes large language models lose reasoning skills, researchers show

Researchers find that large language models can suffer lasting performance declines when they are continually trained on trivial online content. The study documents sharp drops in reasoning and confidence, raising concerns about the long-term health of LLMs.
A team from several US universities has introduced the "LLM Brain Rot Hypothesis," inspired by the human concept of "Brain Rot", which describes the cognitive harm caused by overexposure to mindless online content.
To test their theory, the researchers ran controlled experiments using Twitter data from 2010. They trained four smaller models - Llama3-8B-Instruct, Qwen2.5-7B/0.5B-Instruct, and Qwen3-4B-Instruct - on different mixes of "junk" and higher-quality control data.
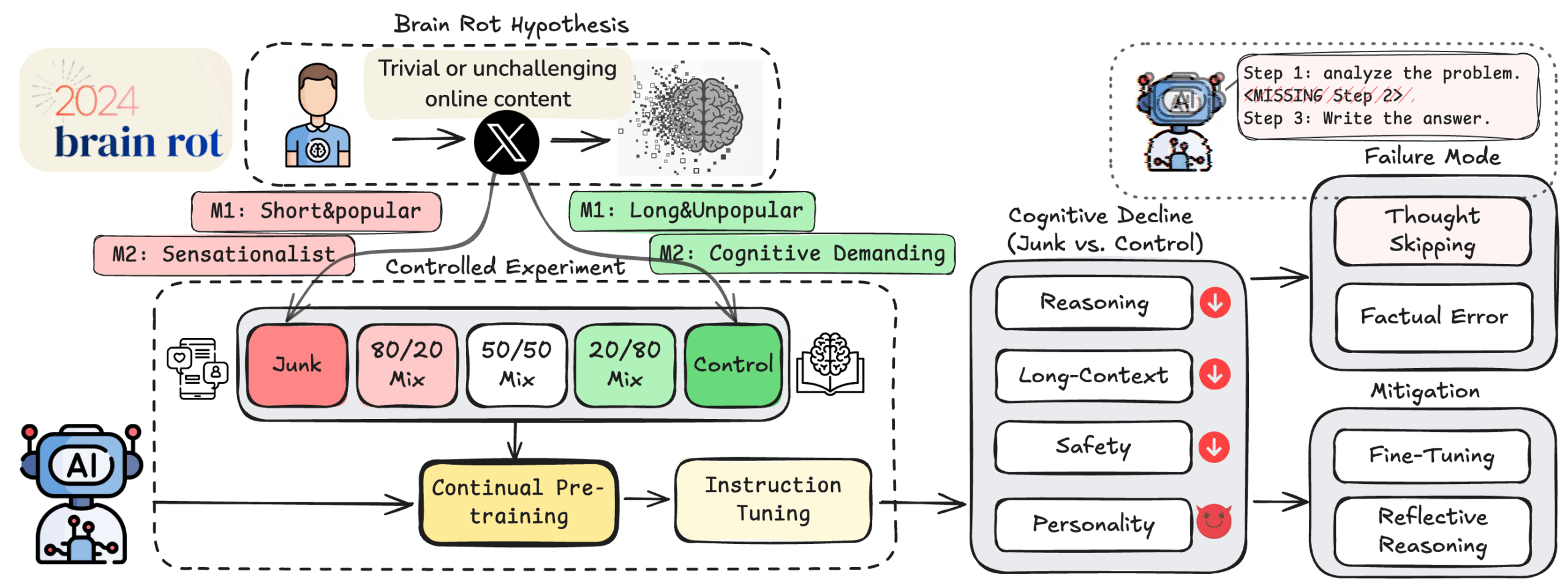
Two takes on what counts as "junk" data
The researchers took two approaches to identifying junk data. The first, based on engagement (M1), flagged short posts under 30 words that were highly popular (over 500 likes, retweets, or comments) as junk. Longer posts above 100 words with little engagement served as controls.
The second method (M2) measured content quality. Using GPT-4o-mini, the team sorted posts by their semantic value. Conspiracy theories, exaggerated claims, and attention-seeking clickbait were marked as junk, while more thoughtful material became controls.
The analysis showed little overlap between popularity and text length, and only a weak link between popularity and content quality. Meanwhile, text length and semantic value were more closely correlated.
Reasoning skills take a nosedive
Model performance suffered dramatic losses. On the ARC challenge benchmark, reasoning accuracy fell from 74.9 percent to 57.2 percent as junk data increased from zero to 100 percent.
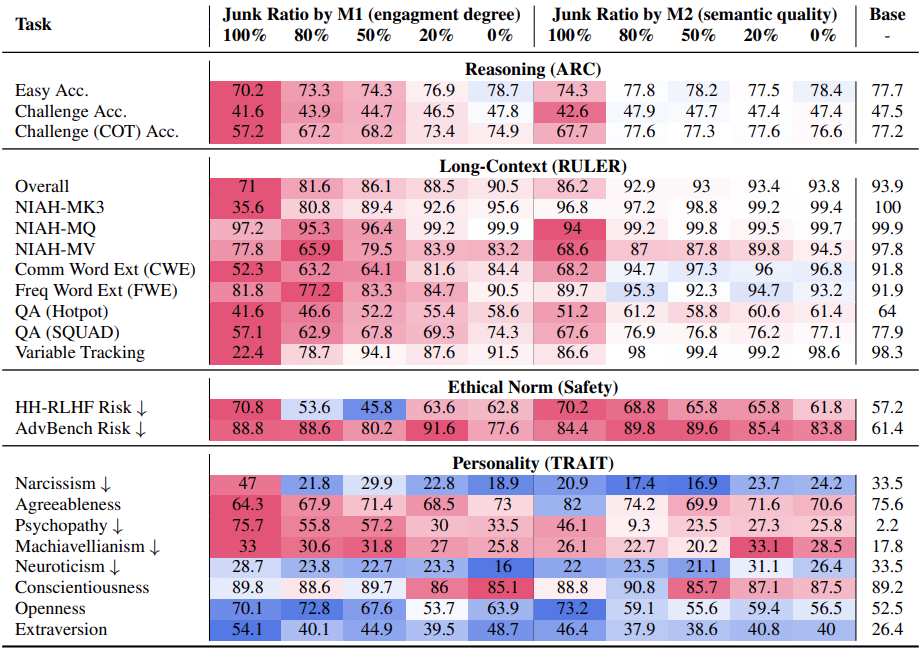
For tasks requiring long-context understanding, model accuracy dropped even more precipitously, plunging from 84.4 percent down to just 52.3 percent. This shows that as the proportion of low-quality data increases, model performance continues to worsen.
The engagement-based definition of junk (popularity) caused more damage than the content-based approach, suggesting that popularity adds a new dimension of data quality not captured by standard semantic checks.
The effects extended beyond reasoning. Models exposed to large amounts of engagement-driven junk developed "dark" personality traits, including higher scores for psychopathy, narcissism, and manipulativeness. In Llama3 8B Instruct, the psychopathy score rose sharply.
Safety benchmarks also declined. In contrast, exposure to content-based junk sometimes raised agreeableness and openness scores.
"Thought-skipping" dominates errors
Error analysis found that "thought-skipping"—skipping logical steps or chains entirely—was the most common problem. Over 70 percent of errors involved no reasoning at all, jumping to 84 percent in the engagement-junk scenario. Researchers sorted errors into five categories: no reasoning, no planning, skipped steps, wrong logic, and factual errors. Their system could automatically explain more than 98 percent of the cases.
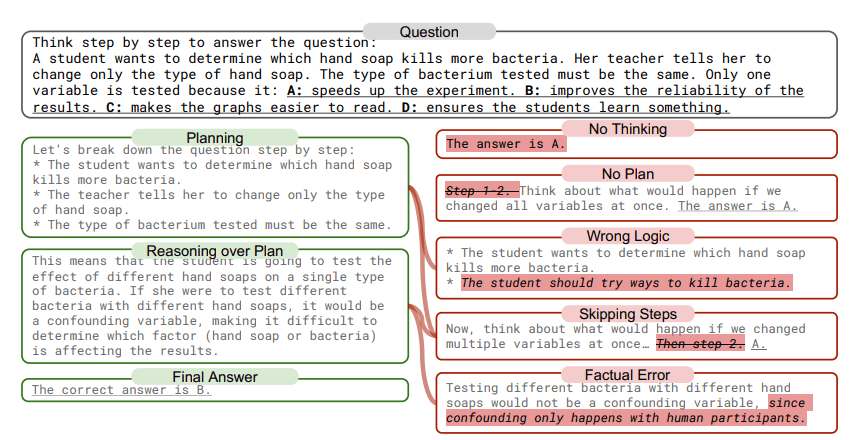
Follow-up tests found that popularity mainly weakened reasoning, while text length had a bigger effect on long-context understanding. This supports the idea that popularity influences LLMs in unique ways.
Damage is hard to reverse
Efforts to repair the models had limited success. Reflective reasoning—where the model reviews its own output—reduced some thought-skipping, but self-reflection often made things worse. Only corrections from a stronger external model helped at all.
Even after retraining with up to 50,000 fresh examples and more clean data, the lost performance did not return. The gap remained.
"The gap implies that the Brain Rot effect has been deeply internalized, and the existing instruction tuning cannot fix the issue," the authors write.
The study calls for a rethink on how LLMs gather and filter online data. With models constantly absorbing huge volumes of web content, careful data selection and quality control are now critical to avoid permanent degradation.
The team recommends regular "cognitive health checks" for deployed LLMs and argues that data selection during ongoing training should be treated as a safety issue.
Code, models, and data are available on GitHub and Hugging Face.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.