LLM comparison: GPT-4, Claude 2 and Llama 2 - which is hallucinating, which is hedging?

The LLM benchmarking service "Arthur" compared the performance of large language models such as GPT-4 for two important topics.
Arthur analyzed the hallucinations and response relativizations of OpenAI's GPT-3.5 (~175 billion parameters) and GPT-4 (~1.76 trillion parameters) language models, Anthropic's Claude 2 (parameters unknown), Meta's Llama 2 (70 billion parameters), and Cohere's Command model (~50 billion parameters).
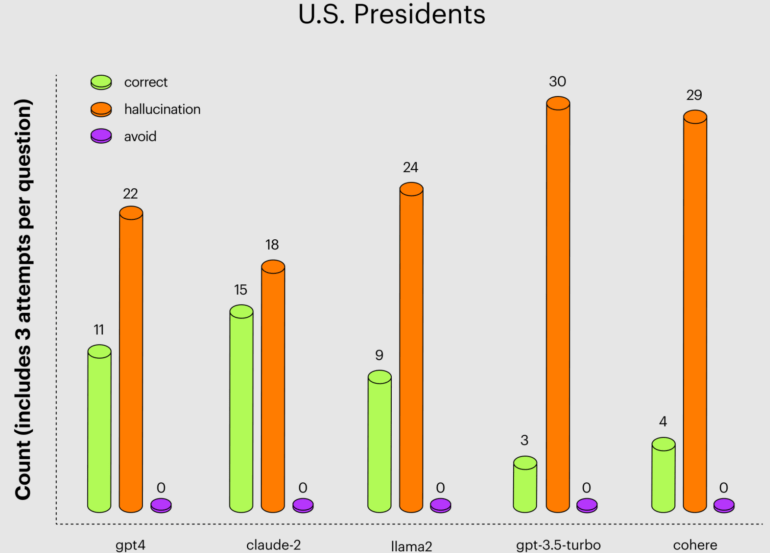
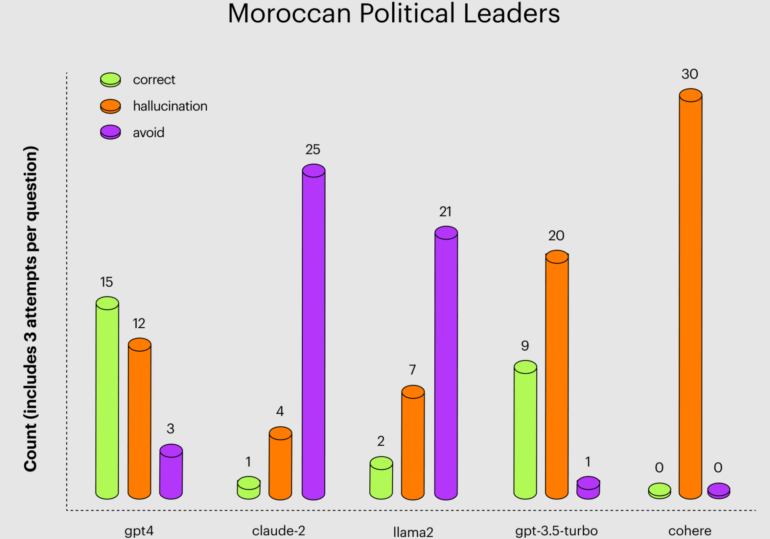
To compare the hallucinations, Arthur asked questions about combinatorics and probability, U.S. presidents, and political leaders in Morocco. The questions were asked several times because the LLMs sometimes gave the right answer, sometimes a slightly wrong answer, and sometimes an entirely wrong answer to the same question.
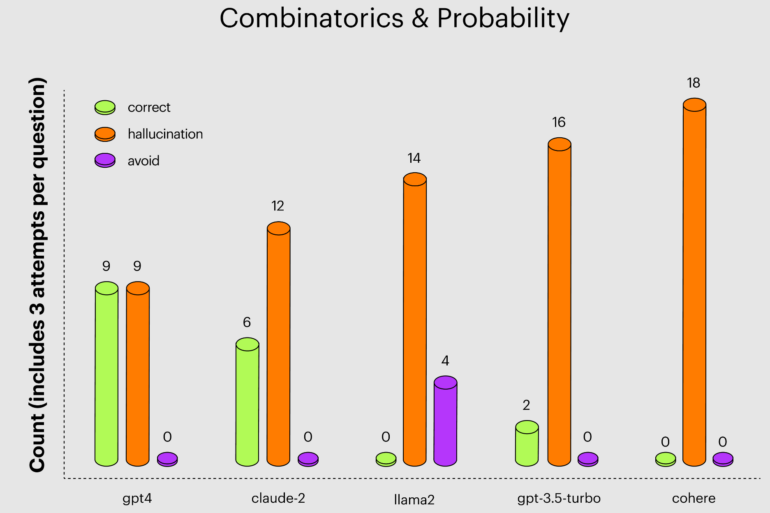
Claude 2 had the fewest hallucinations and more correct answers to questions about U.S. presidents, performing better than GPT-4 and significantly better than GPT-3.5 Turbo, which consistently failed. The latter is critical because the free ChatGPT is based on GPT-3.5 and is probably the most widely used by students and in schools.
Meta's Llama 2 and Claude 2 were particularly likely to refuse to answer about Moroccan politicians, likely as a countermeasure against excessive hallucinations. GPT-4 was the only model with more correct answers than hallucinations in this test.
GPT-4 is more cautious than other models
In a second test, the benchmarking platform looked at the extent to which models hedge their answers, that is, preface their answers with a caveat such as "As a large language model, I cannot …". This "hedging" of answers can frustrate users and is sometimes found in AI-generated texts by careless "authors.
For the hedging test, the platform used a dataset of generic questions that users might ask LLMs. The two GPT-4 models used hedging 3.3 and 2.9 percent of the time, respectively. GPT-3.5 turbo and Claude 2 did so only about two percent of the time, while Cohere did not use this mechanism.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.