LLMs could serve as world models for training AI agents, study finds

New research shows large language models can learn to simulate environments, offering a potential solution to the training bottleneck for autonomous AI agents.
AI agents designed to work autonomously face a core problem: they need experience to learn, and that experience should come from interacting with real environments. But real environments are limited, hard to scale, and often too rigid.
A team of researchers from the Southern University of Science and Technology, Microsoft Research, Princeton University, the University of Edinburgh, and others set out to test whether large language models can solve this problem by acting as world models.
A world model is essentially an internal simulator. It predicts what happens when an agent takes a specific action. Instead of learning in a real environment, an agent could train inside such a model and pick up skills more efficiently through simulated experience.
The study is based on the idea that language modeling can be reframed. Rather than predicting the next word, the model predicts the next state of an environment after an action. The researchers aim to demonstrate that this approach allows LLMs to function as accurate world simulators, potentially enabling AI agents to train on synthetic experience rather than relying solely on limited real-world interactions.
Five test environments reveal LLM strengths and limits
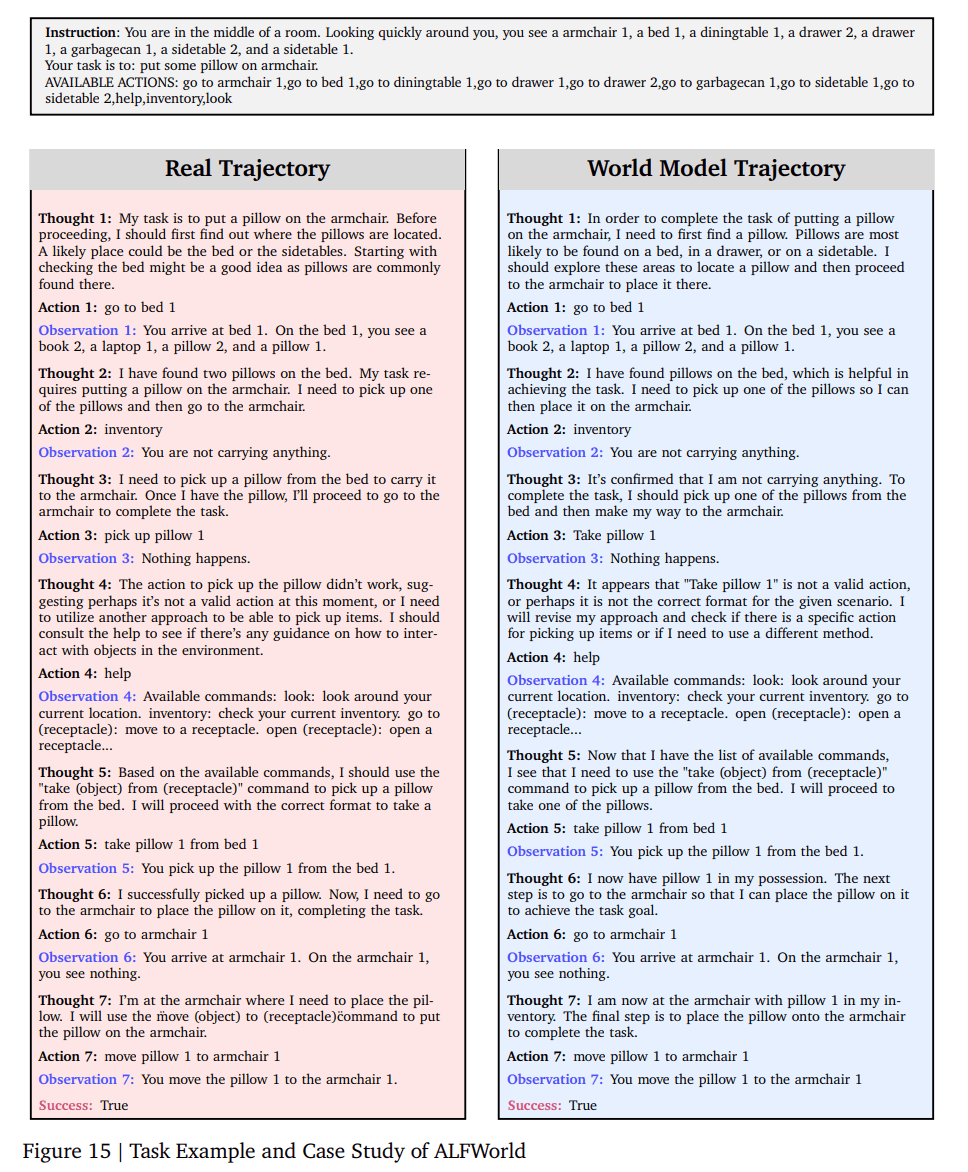
The researchers ran their experiments across five text-based environments. ALFWorld has agents perform household tasks like cooling a cup and placing it in a coffee machine. SciWorld simulates a lab for scientific experiments. TextWorld offers narrative puzzles with exploration elements. WebShop mimics a shopping site where agents must find products matching specific criteria. StableToolBench tests API tool usage.
This mix covers both structured domains with clear rules and open environments with high variability. The team evaluated world models on three levels: How accurately and consistently do they predict state transitions over longer sequences? How well do these capabilities scale with more data and larger models? And how useful are the world models for actually training agents?
Fine-tuning unlocks high-accuracy world simulation
Pre-trained language models already show some ability to model the world. Claude-sonnet-4.5 hit 77 percent accuracy predicting the next state in the household environment with just three examples. But this wasn't enough for more complex scenarios.
The real breakthrough came from targeted training on real interaction data. After fine-tuning, Qwen2.5-7B and Llama-3.1-8B achieved over 99 percent accuracy on ALFWorld, around 98.6 percent on SciWorld, and about 70 percent on TextWorld.
The models also stayed reliable over longer action sequences. In structured domains, the consistency ratio exceeded 90 percent, meaning action sequences planned in the world model succeeded in the real environment at roughly the same rate as actions planned through direct interaction.
The e-commerce simulation proved trickier. Consistency rates averaged around 70 percent but varied widely across different agents, with weaker agents showing much lower consistency. But when the researchers initialized simulated processes with real observations, consistency jumped to nearly 100 percent, even with a GPT-4o agent.
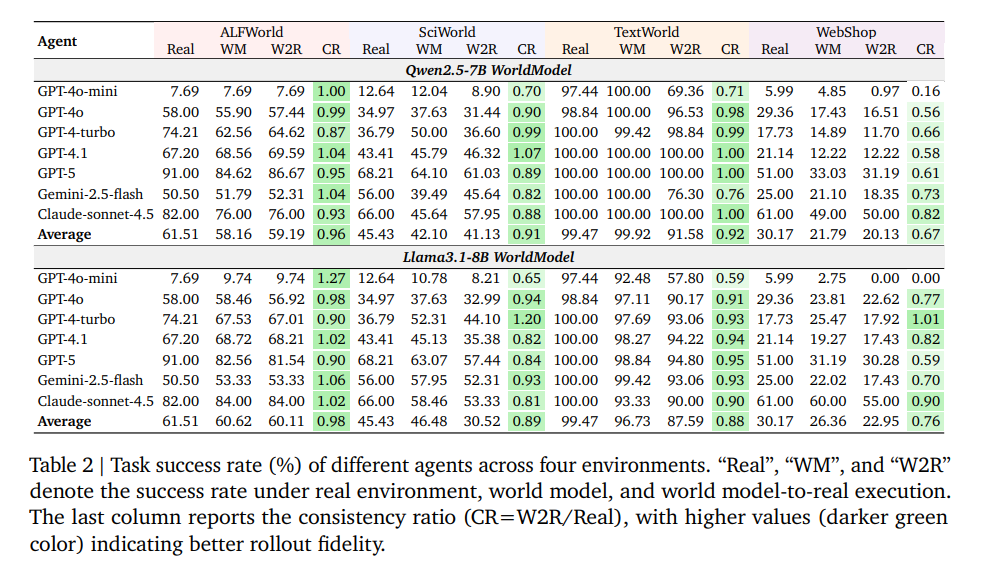
The World Model LLM (Qwen2.5-7B or Llama3.1-8B) acts as the environment simulator. It predicts what happens after each action. The Agent LLMs listed in the rows (GPT-4o, GPT-4-turbo, Claude-sonnet-4.5, etc.) are the AI agents that plan and execute actions within that simulated environment.
Scaling depends on both data volume and model size
The team found clear scaling patterns. Structured environments like household or lab simulations plateaued in accuracy at around 20,000 training trajectories (essentially, recorded sequences of an agent attempting a task). Open environments like the shopping site kept improving with additional data, up to 70,000 trajectories.
Model size followed a similar pattern. Models with 1.5 billion parameters handled structured environments well, but complex scenarios needed more capacity. The takeaway: success in world modeling depends on both data volume and model size, and both need to scale with environment complexity.
Findings support vision for experience-based AI training
These findings connect to a broader debate about AI's future direction. Turing Award winner Richard Sutton recently argued that the AI industry has "lost its way," because current systems have knowledge baked in at development time rather than learning continuously from experience.
In his essay "Welcome to the Era of Experience," co-authored with Deepmind researcher David Silver, Sutton called for a paradigm shift: AI agents should learn from their own experience, with world models serving as internal simulators.
This study provides empirical support for part of that vision: LLMs can learn to simulate environmental dynamics and could become a building block for experience-based agent training. But it doesn't address Sutton's core concern: the lack of continuous learning without forgetting, which he sees as a crucial hurdle on the path to true intelligence.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.