Lumiere: Google shows new generative AI for realistic videos

Google introduces a new text-to-video model that outperforms alternative models and can be seen as a new standard.
Google researchers have developed a new text-to-video (T2V) diffusion model called Lumiere that is capable of generating realistic AI videos that overcome many of the problems of alternative approaches.
Lumiere uses a new Space-Time U-Net (STUNet) architecture that enables the generation of videos with coherent motion and high quality. The method is fundamentally different from previous approaches based on a cascade of models that can only process parts of the video at a time.
Lumiere can also be used for other applications such as video inpainting, image-to-video generation, and stylized video. The model was trained on 30 million videos and shows competitive results in terms of video quality and text matching compared to other methods. The model was trained on 30 million videos with associated text captions. The videos have a length of 80 frames at 16 frames per second (fps) and last 5 seconds each. The model is based on a pre-trained frozen text-to-image model, which was extended by additional layers for video-relevant aspects such as the temporal dimension.
Google's Lumiere relies on spatial and temporal down- and up-sampling
Unlike previous T2V models, which first generate keyframes and then use Temporal Super-Resolution (TSR) models to insert missing frames between those keyframes, Lumiere generates the entire video sequence at once. This allows for more coherent and realistic motion throughout the video.
This is made possible by the STUNet architecture, which not only downsamples and then upsamples the spatial resolution like existing methods, but also the temporal resolution. The number of frames per second in a video is downsampled and then upsampled again. By downsampling, the model processes the video at this reduced temporal resolution but still sees the full length of the video - just with fewer frames. In this way, the model learns how objects and scenes move and change over this reduced number of frames.
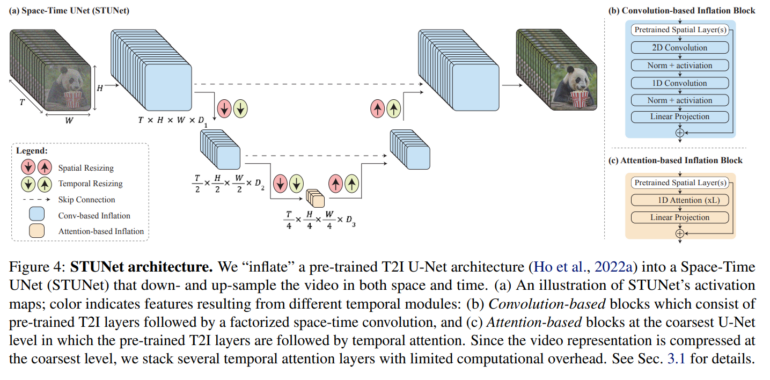
Once the model has learned the basic motion patterns at this reduced resolution, it can build on them to improve the final video quality at full temporal resolution. This process allows for more efficient handling of the video without compromising the quality of the generated motion and scenes.
Once the video has been generated at this lower temporal and spatial resolution, Lumiere uses Multidiffusion for spatial super-resolution (SSR). This involves dividing the video into overlapping segments and enhancing each segment individually to increase resolution. These segments are then stitched together to create a coherent, high-resolution video. This process makes it possible to produce high-quality video without the massive resources required for direct high-resolution production.
According to Google, Lumiere outperformed existing text-to-video models such as Imagen Video, Pika, Stable Video Diffusion, and Gen-2 in a user study. Despite its strengths, much remains to be done: Lumiere is also not designed to generate videos with multiple scenes or transitions between scenes, which poses a challenge for future research.
More examples and information can be found on the Lumiere project page.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.