Meta's new MILS system teaches LLMs to handle multimedia data without specialized training

Meta AI researchers and their academic partners have developed a system that teaches large language models to handle images, video, and audio without specialized training.
Called MILS (Multimodal Iterative LLM Solver), the system relies on the models' natural problem-solving abilities instead of extensive data training.
MILS works by pairing two AI models: a "generator" that proposes solutions to tasks, and a "scorer" that evaluates how well those solutions work. The scorer's feedback helps the generator improve its answers step by step until it reaches a satisfactory result.
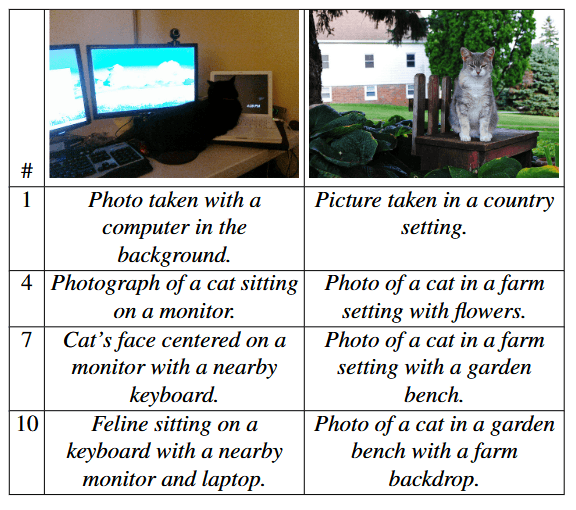
The system shows particular strength in describing images. Using Llama-3.1-8B as its generator and CLIP as its scorer, MILS creates detailed image descriptions that match or exceed current leading methods - even though CLIP wasn't specifically trained for this task.
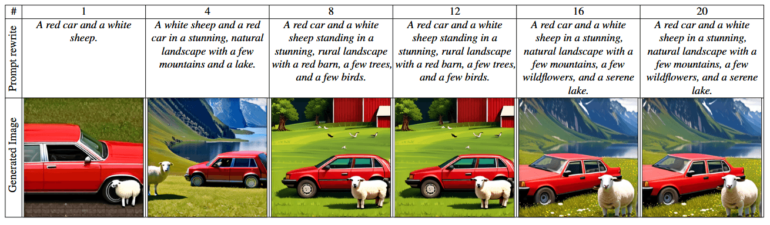
MILS also enhances text-to-image generation by fine-tuning text prompts, and can handle image editing tasks like style transfer by combining AI-generated prompts with image processing tools.
The system's capabilities extend to video and audio as well. In tests using the MSR-VTT video dataset, MILS performed better than existing models at describing video content.
Since MILS doesn't modify model parameters during operation, it can convert different types of data into readable text. This allows for new applications, like combining information from multiple sources - such as images and audio - by converting everything to text, merging the information, and then converting it back into the desired format.
Tests indicate that larger generator and scorer models produce more accurate results, and that having more potential solutions to work with improves performance. The researchers found that scaling up to larger language models also led to noticeable quality improvements.
AI assistants learn to see and hear
The AI landscape is quickly shifting toward models that can handle multiple types of input, so-called multimodality. While OpenAI's GPT-4o led the way, open-source alternatives are catching up: Meta's Llama 3.2, Mistral's Pixtral, and DeepSeek's Janus Pro can all process images alongside text - a key feature for AI systems that aim to be truly helpful in everyday situations.
MILS takes a different approach to multimodality by moving the training requirements to a pre-trained scorer model. This strategy fits with the field's current direction of enhancing language models through smarter inference methods instead of just adding more training data. Looking ahead, the research team sees potential for MILS to tackle 3D data processing as well.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.