Meta's ImageBind is a new multimodal model that combines six data types. Meta is releasing it as open source.
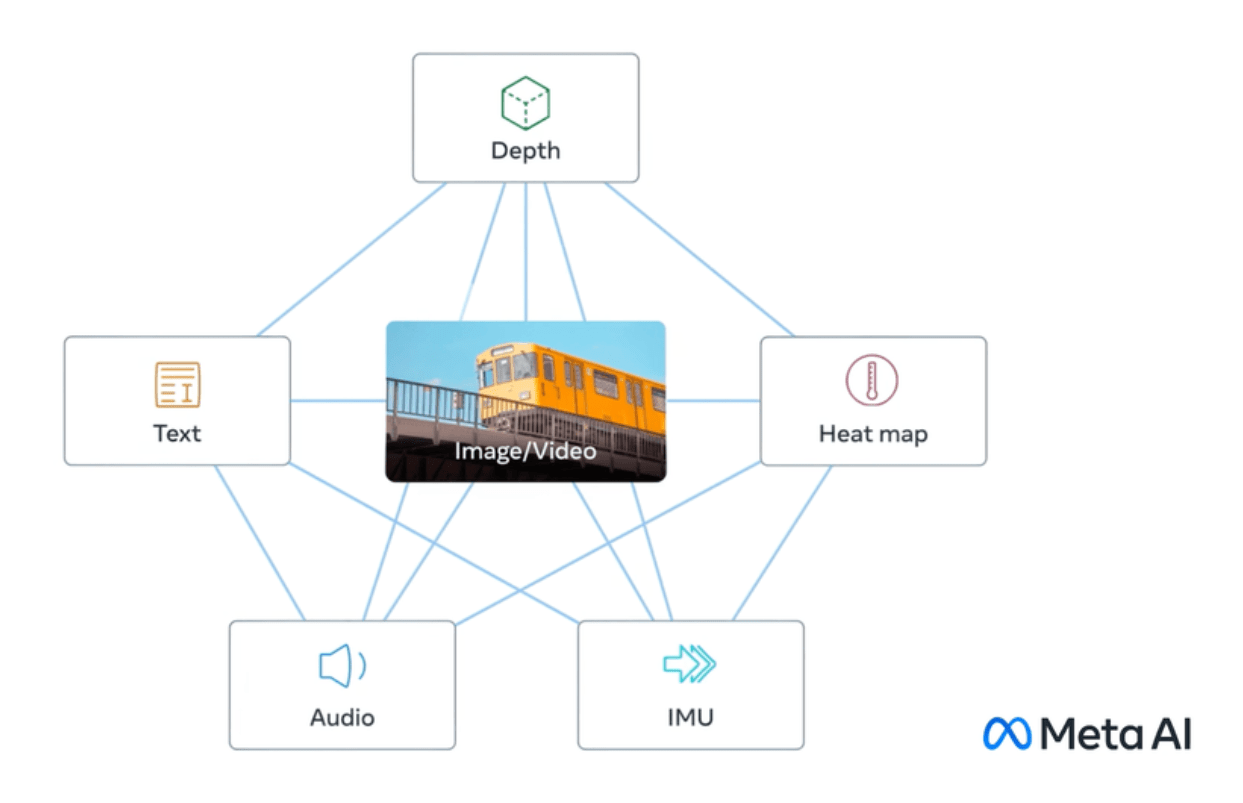
ImageBind makes the metaverse seem a little less like a distant vision of the future: In addition to text, the AI model understands audio, visual, motion sensor, thermal, and depth data.
At least in theory, this makes it a versatile building block for generative AI models. For example, it could serve as the basis for generative models that combine sensor data and 3D to design immersive virtual worlds (VR), Meta writes, or augment reality with context-sensitive digital data (AR). VR and AR are two key technologies in Meta's long-term vision of the Metaverse.

As other examples, Meta cites a video of a sunset that is automatically accompanied by a matching sound clip, or a picture of a Shih Tzu that generates 3D data of similar dogs, or an essay about the breed.
For a video created with a model like Meta's Make-A-Video, ImageBind could help a generative AI model generate the appropriate background sounds or predict depth data from a photo.
AI systems often work with different types of data (called modalities), such as images, text, and sound. AI understands and relates these different types of data by converting them into lists of numbers - called embeddings - and combining them into a shared space. These embeddings help the AI recognize the information contained in the data and establish relationships between them.
What makes ImageBind unique is that it creates a common language for these different types of data without requiring examples that contain all the data types. Such datasets would be costly or impossible to obtain.
This is achieved by using large vision language models, AI models trained to understand both images and text. ImageBind extends the ability of these models to process new modalities, such as video-audio and depth image data, by leveraging the natural connections between these data types and images.
Image data as a bridge between modalities
ImageBind uses unstructured data to integrate four additional modalities (audio, depth, thermal, and IMU). AI can learn from the natural connections between data types without the need for explicit markers-hence the name of the model that binds all data to images.

Meta says this works because images can often be combined with various other modalities and used as a bridge between them. For example, images and text often appear together on the Web, so the model can learn the relationship between them.
Similarly, motion data from wearable cameras with IMU sensors can be paired with corresponding video data. By leveraging these natural pairings, ImageBind creates a shared embedding space that allows AI to better understand and work with multiple modalities.
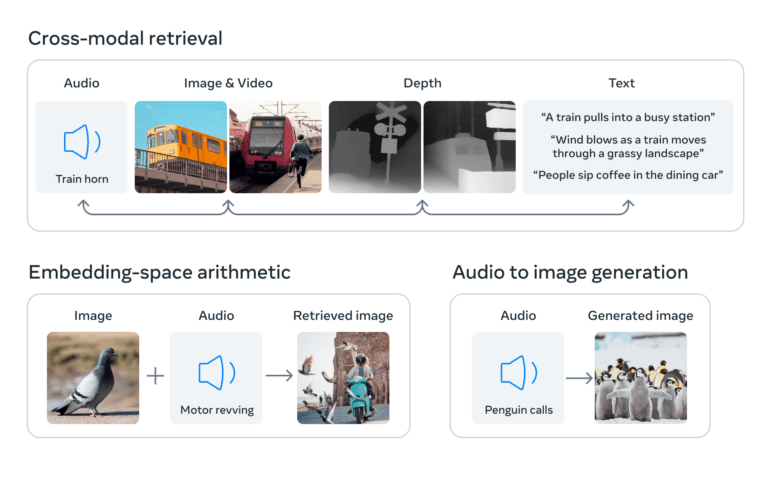
ImageBind shows that image-paired data is sufficient to bind together these six modalities. The model can interpret content more holistically, allowing the different modalities to “talk” to each other and find links without observing them together. For example, ImageBind can associate audio and text without seeing them together. This enables other models to “understand” new modalities without any resource-intensive training.
Meta
ImageBind is like a shortcut that helps AI understand and more easily connect different types of data. With this model, AI researchers can more efficiently explore the relationships between different types of data and develop more versatile AI models.
In the future, the model could be expanded to include other sensory data, such as touch, speech, smell, and even fMRI signals from the brain, Meta writes. This would bring machines closer to the human ability to learn simultaneously, holistically, and directly from many different types of information.
Meta releases the code for ImageBind as open source on Github under a CC-BY-NC 4.0 license, which does not allow commercial use.



